Java开发知识点总结
redis
redis几种数据结构
《redis设计与实现》
- 动态字符串 数据结构为1,长度len,2,buf,3,free
- 双端链表
- 字典
数据结构,哈希数组 - 跳跃表
redis只在两个地方用的了跳表,1是有序集合键,2是集合节点中用作内部结构 Rogn|SkipList的基本原理 - 整数集合 intset
- 压缩列表
ziplist,

- 对象
- Redis数据库中的每个键值对的键和值都是一个对象。
- Redis共有字符串、列表、哈希、集合、有序集合五种类型的对象,每种类型的对象至少都有两种或以上的编码方式, 不同的编码可以在不同的使用场景上优化对象的使用效率。
- 服务器在执行某些命令之前,会先检查给定键的类型能否执行指定的命令,而检查 一个键的类型就是检查键的值对象的类型。
- Redis的对象系统带有引用计数实现的内存回收机制,当一个对象不再被使用时,该 对象所占用的内存就会被自动释放。
- Redis会共享值为0到9999的字符串对象。
- 对象会记录自己的最后一次被访问的时间,这个时间可以用于计算对象的空转时间。

typedef struct redisObject {
//类型 对象类型
unsigned type:4;
//编码 即对象是使用什么数据结构作为对象的底层实现
unsigned encoding:4;
//指向底层实现数据结构的指针
void * ptr;
//...
}- 字符串对象编码可以是:int、raw或者embstr;命令set xxx xxx
- 列表对象编码是:ziplist或者linkedlist;命令lpush、rpush、llen
- 哈希对象编码可以是:ziplist或者hashtable;命令hset strings "key" "xxx"、hget
- 集合对象编码可以是:intset或者hashtable;命令sadd numbers 1 3 5
- 有序集合的编码可以是:ziplist或者skiplist;命令zadd set 1.2 apple
redis gc
redis基于C语言并实现了引用计数的垃圾回收机制
每个对象的引用计数信息由redisObject结构的refcount属性记录:
typeof struct redisObject {
// ...
// 引用计数
int refcount;
// ...
}robj;redis的线程模型
单线程
Redis is single-threaded, then how does it do concurrent I/O?|stackoverflow
redis cluster模式
redis cluster模式下数据怎么读写,槽位迁移时数据是否会丢失。
集群节点间通信是用Gossip协议。
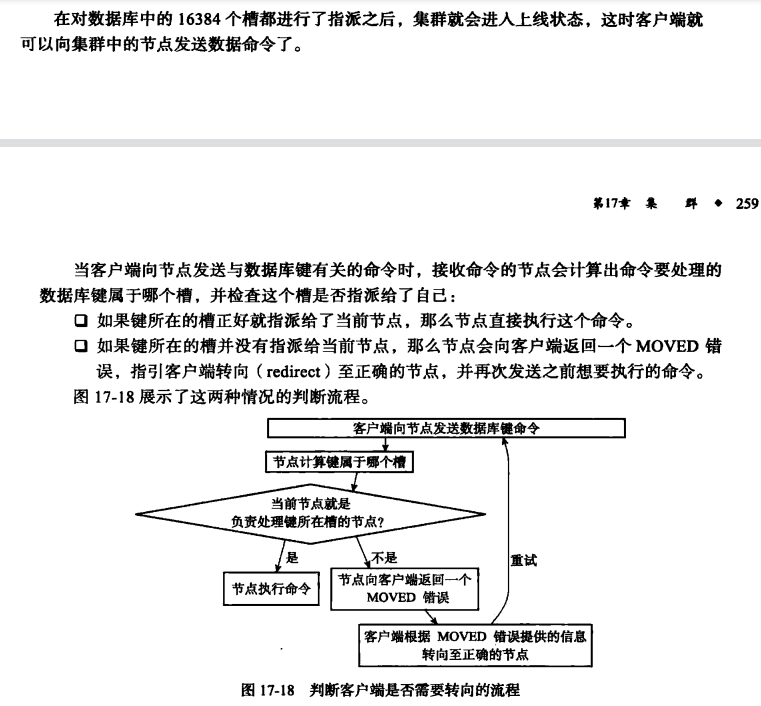
Redis学习笔记七——向集群节点添加、删除和分配slot|哈利路亚--Java
槽位迁移时数据是否会丢失: 不会,要双方执行集群(cluster)命令,一个importing一个migrating,中途中断可以恢复的。 redis迁移数据之槽道讨论
双活方案
- 热备
- 跨IDC同步
- 应用双写
方案一:热备
1.常规情况
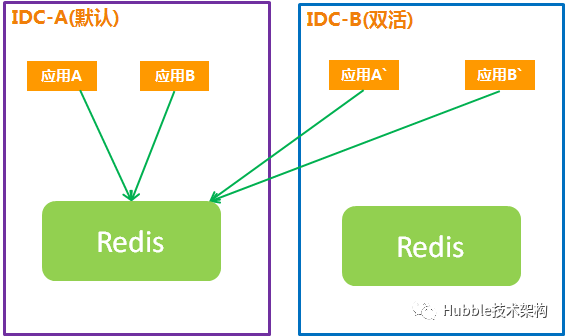
双活IDC的应用连接主IDC的Redis。
双活IDC的Redis处于启动状态,随时可以连接。
2.容灾切换
主IDC故障,切换到双活:
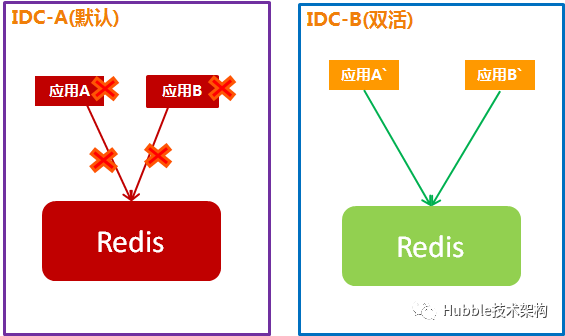
主IDC故障应用、Redis都不能用,双活IDC的应用切到连接双活IDC的Redis,并承担100%流量访问。
Redis容灾切换时,Redis数据会全部丢失,影响系统业务功能,使用时要评估每种业务场景的影响。
a、共享会话丢失,用户需要重新登录(对应用体验有影响)。
b、计数器归零,对计数器有依赖的场景(库存扣减、秒杀等)有比较大的风险。
c、缓存数据丢失,需要查询DB重建缓存,命中率降为0(缓存击穿)。
d、分布式锁会失效,原子性被破坏。
3.故障恢复
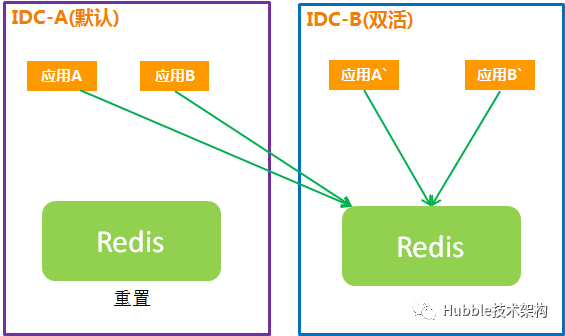
1、主IDC恢复之后须重启清空Redis数据,避免脏数据影响业务准确性。
2、主IDC、双活IDC的应用都连接双活IDC的Redis。
3、故障机房完全恢复后,在业务最低峰期再把主IDC,双活IDC切到主IDC的Redis,达到故障完全恢复。
4.总结
此方案的优点是架构简单,故障时切换即可。
但Redis切换时,数据丢失,Redis重置,需要细致评估每个Redis使用场景,是否能接受
方案二:跨IDC同步
Redis跨IDC同步,是在热备的基础上增加了Redis数据跨IDC“增量”同步的功能。
1.常规情况
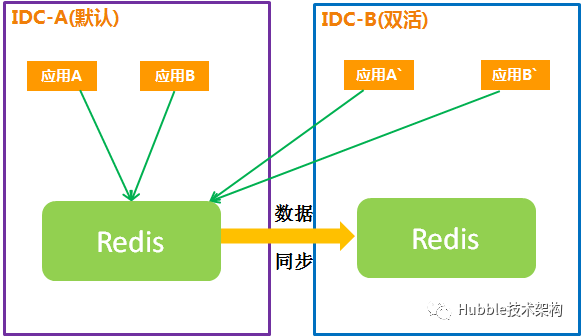
主IDC的Redis数据通过Redis-Shake的Sync/Psync模式全量或增量实时同步到双活IDC。
2.容灾切换
主IDC的故障,切换到双活IDC: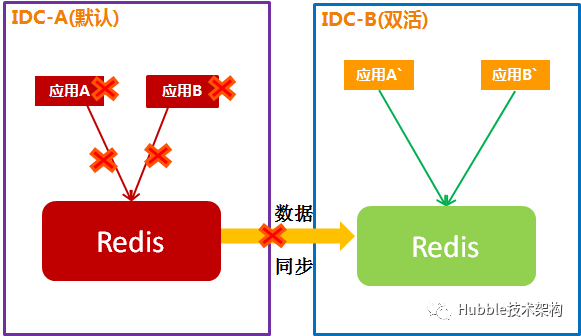
Redis是跨IDC同步,在故障的瞬间可能会有1-3秒的数据未同步完成。Redis场景基本上读多写少,对业务影响不大。
3.故障恢复
主IDC的应用及Redis恢复,需要切回主IDC:
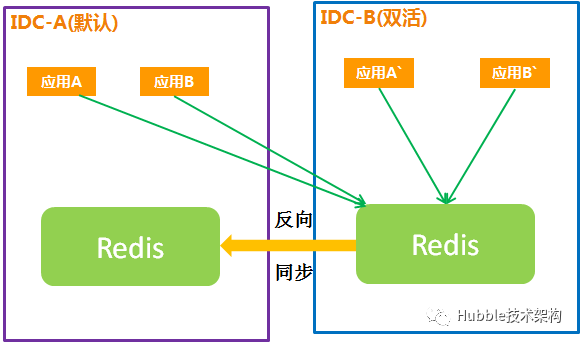
说明:
1、主IDC应用、双活IDC应用都连接到双活IDC的Redis。
2、为保证Redis数据的一致性,双活IDC的Redis反向同步到主IDC,以备后续切为主IDC。
4.总结
Redis基本上,读多写少,跨IDC同步,保证数据不丢,基本上保证数据一致性,技术上是可行的,对“热备”方案是一个很好补充。
短期,进入双活环境的流量也不大,读多写少。跨IDC同步虽有一定延时,一致性上基本能接受。
注:跨IDC访问存在5-8毫秒延时。
方案三:应用双写(不推荐)
应用双写是指应用同时连接主IDC、双活IDC,写数据时同时写两个IDC的Redis,读数据时只读同IDC的Redis。
通过应用双写来实现两个IDC的数据一致性。
1.常规情况
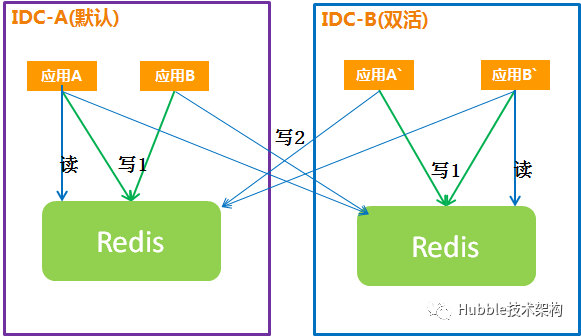
说明:
1、应用同时连接两个IDC的Redis,写数据时同时,写两个Redis。
2、应用只读同IDC的Redis。
问题点:
1、应用实现双写,应用需要改代码。需要收集所有”写“请求的点,进行代码改造。
2、如果程序员在版本迭代过程中,漏掉了一些点,将会产生数据不一致,而且不容易把问题测试出来。
而且,在双写的代码中,Redis原子操作无法保障,程序员如果对异常处理不当,当其中某一集群故障时,就会导致业务不可用。
这点上,对研发、测试要求太高,也容易出问题。
3、应用双写,如果其中一个集群故障一小段时间,则会产生两个集群数据不一致,意味着有个集群是不对的,而且无法进行对账和补偿,需要干掉其中一个。运维都无法识别和处理。
- 容灾切换
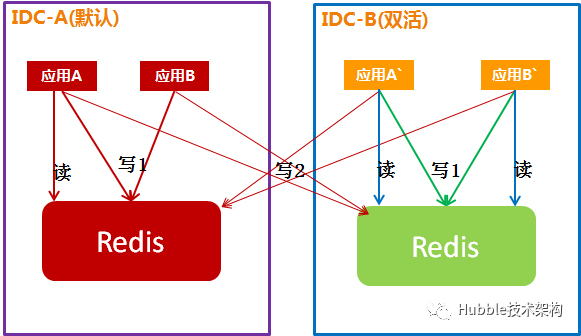
主IDC故障期间,双活IDC跨IDC写会失败,会产生大量异常,并影响到业务功能。
- 故障恢复

当主IDC故障恢复后,两个Redis的数据已经不一致。主IDC Redis集群的数据无法进行增量补偿,无法解决两个集群数据不一致问题。
这个问题是致命的。
缓存穿透
所谓缓存穿透就是说在缓存中不存在,然后直接在数据库中查询的现象
解决:
- 存储null值
- 参数校验
- 布隆过滤器
布隆过滤器|百度百科 详解布隆过滤器的原理,使用场景和注意事项|知乎
缓存雪崩
所谓缓存雪崩就是在某一个时刻,缓存集大量失效。所有流量直接打到数据库上,对数据库造成巨大压力;
解决(看具体业务定):
- 设置值时过期时间加上随机时间,设置更进一步,某些(热点)数据做到自适应延长时间
- 缓存标记 给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存
Redis Mybatis二级缓存
二级缓存和一级缓存的原理是一样的,第一次查询,会将数据放入缓存中,然后第二次查询则会直接去缓存中取。但是一级缓存是基于的sqlSession,而二级缓存是基于mapper文件的namespace的,也就是说多个sqlSession可以共享一个mapper中的二级缓存区域,并且如何两个mapper的namespace相同,即使两个mapper,那这两个mapper中执行sql查询到的数据也将存在相同的二级缓存区域中
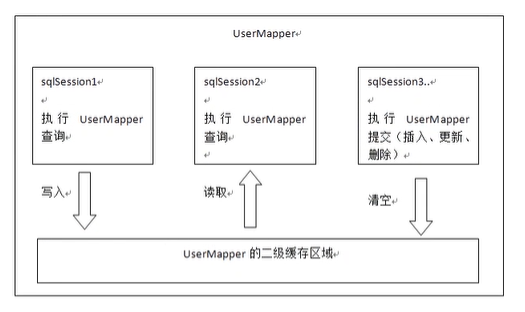
https://www.cnblogs.com/isdxh/p/13963636.html
kafka
kafka为什么高性能,怎么保证消息不丢不重
原理
不丢不重看ack级别和011版本后的幂等性校验。当然011后的幂等性配置只能保证同分区。所以消费者落地时仍然要根据数据自行校验。
性能
知乎|Kafka高性能原理
聊聊page cache与Kafka之间的事儿
Linux系统中的Page cache和Buffer cache
Kafka为什么速度那么快?
命令
分布式事务
ACID:
- 原子性
- 一致性
- 隔离性
- 持久性
种类:
- 2PC 同步阻塞协议 2PC 是一种尽量保证强一致性的分布式事务,因此它是同步阻塞的,而同步阻塞就导致长久的资源锁定问题,总体而言效率低,并且存在单点故障问题,在极端条件下存在数据不一致的风险。
- 3PC
所以 2PC 和 3PC 都不能保证数据100%一致,因此一般都需要有定时扫描补偿机制。
我再说下 3PC 我没有找到具体的实现,所以我认为 3PC 只是纯的理论上的东西,而且可以看到相比于 2PC 它是做了一些努力但是效果甚微,所以只做了解即可。 - TCC
2PC 和 3PC 都是数据库层面的,而 TCC 是业务层面的分布式事务,就像我前面说的分布式事务不仅仅包括数据库的操作,还包括发送短信等,这时候 TCC 就派上用场了!
TCC 指的是Try - Confirm - Cancel。 可以看到流程还是很简单的,难点在于业务上的定义,对于每一个操作你都需要定义三个动作分别对应Try - Confirm - Cancel。
TCC 对业务的侵入较大和业务紧耦合,需要根据特定的场景和业务逻辑来设计相应的操作。
还有一点要注意,撤销和确认操作的执行可能需要重试,因此还需要保证操作的幂等。 - 本地消息表
本地消息表其实就是利用了 各系统本地的事务来实现分布式事务。
本地消息表顾名思义就是会有一张存放本地消息的表,一般都是放在数据库中,然后在执行业务的时候 将业务的执行和将消息放入消息表中的操作放在同一个事务中,这样就能保证消息放入本地表中业务肯定是执行成功的。
然后再去调用下一个操作,如果下一个操作调用成功了好说,消息表的消息状态可以直接改成已成功。
如果调用失败也没事,会有 后台任务定时去读取本地消息表,筛选出还未成功的消息再调用对应的服务,服务更新成功了再变更消息的状态。
这时候有可能消息对应的操作不成功,因此也需要重试,重试就得保证对应服务的方法是幂等的,而且一般重试会有最大次数,超过最大次数可以记录下报警让人工处理。
可以看到本地消息表其实实现的是最终一致性,容忍了数据暂时不一致的情况。
- 消息事务
RocketMQ 就很好的支持了消息事务,让我们来看一下如何通过消息实现事务。
第一步先给 Broker 发送事务消息即半消息,半消息不是说一半消息,而是这个消息对消费者来说不可见,然后发送成功后发送方再执行本地事务。
再根据本地事务的结果向 Broker 发送 Commit 或者 RollBack 命令。
并且 RocketMQ 的发送方会提供一个反查事务状态接口,如果一段时间内半消息没有收到任何操作请求,那么 Broker 会通过反查接口得知发送方事务是否执行成功,然后执行 Commit 或者 RollBack 命令。
如果是 Commit 那么订阅方就能收到这条消息,然后再做对应的操作,做完了之后再消费这条消息即可。
如果是 RollBack 那么订阅方收不到这条消息,等于事务就没执行过。
可以看到通过 RocketMQ 还是比较容易实现的,RocketMQ 提供了事务消息的功能,我们只需要定义好事务反查接口即可。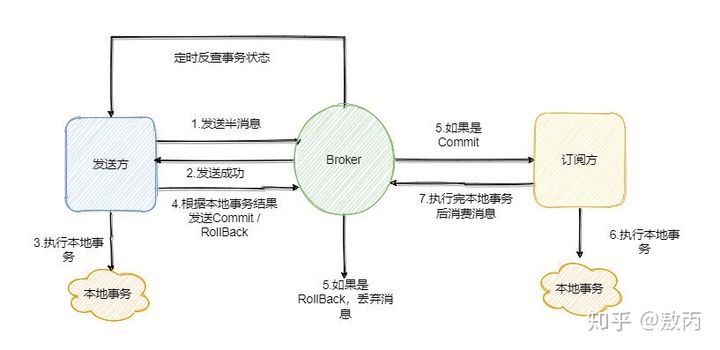
- 最大努力通知
其实我觉得本地消息表也可以算最大努力,事务消息也可以算最大努力。
就本地消息表来说会有后台任务定时去查看未完成的消息,然后去调用对应的服务,当一个消息多次调用都失败的时候可以记录下然后引入人工,或者直接舍弃。这其实算是最大努力了。
事务消息也是一样,当半消息被commit了之后确实就是普通消息了,如果订阅者一直不消费或者消费不了则会一直重试,到最后进入死信队列。其实这也算最大努力。
所以最大努力通知其实只是表明了一种柔性事务的思想:我已经尽力我最大的努力想达成事务的最终一致了。
适用于对时间不敏感的业务,例如短信通知。
JVM
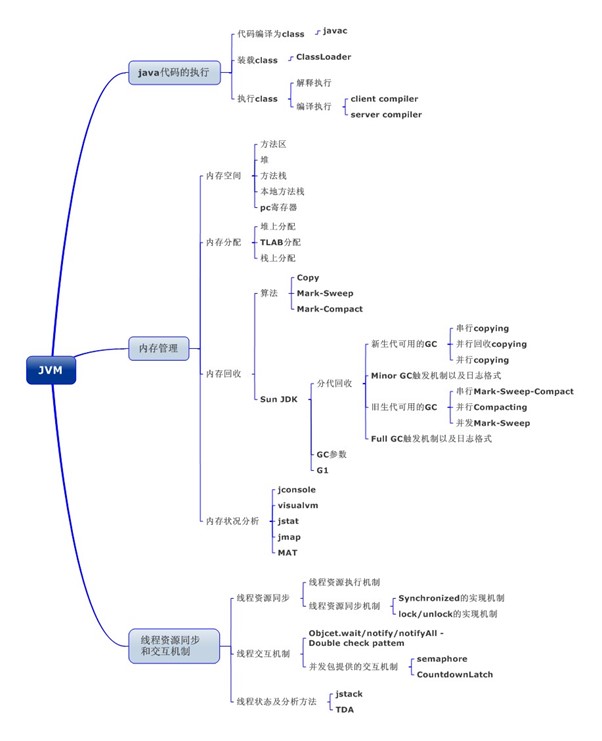
JVM内存
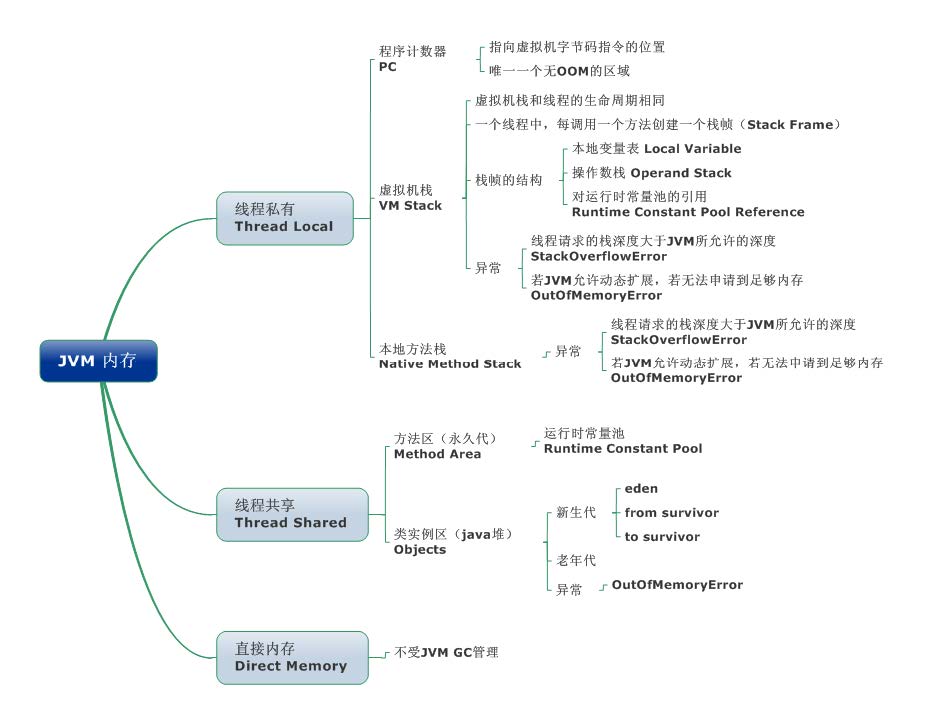
JVM的运行时数据区域|Java api learning|Tea's Blog
直接内存并不是JVM运行时数据区的一部分, 但也会被频繁的使用: 在JDK 1.4 引入的NIO 提 供了基于Channel 与Buffer 的IO 方式, 它可以使用Native 函数库直接分配堆外内存, 然后使用 DirectByteBuffer 对象作为这块内存的引用进行操作(详见: Java I/O 扩展), 这样就避免了在Java 堆和Native 堆中来回复制数据, 因此在一些场景中可以显著提高性能。
程序计数器(线程私有)
一块较小的内存空间, 是当前线程所执行的字节码的行号指示器,每条线程都要有一个独立的程序计数器,这类内存也称为“线程私有”的内存。
正在执行java方法的话,计数器记录的是虚拟机字节码指令的地址(当前指令的地址)。如果还是Native方法,则为空。
这个内存区域是唯一一个在虚拟机中没有规定任何OutOfMemoryError情况的区域。
虚拟机栈(线程私有)
是描述java方法执行的内存模型,每个方法在执行的同时都会创建一个栈帧(StackFrame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
栈帧(Frame)是用来存储数据和部分过程结果的数据结构,同时也被用来处理动态链接(Dynamic Linking)、方法返回值和异常分派(Dispatch Exception)。栈帧随着方法调用而创建,随着方法结束而销毁——无论方法是正常完成还是异常完成(抛出了在方法内未被捕获的异常)都算作方法结束。
TLAB
在多线程运行时,需要分配给新建对象分配内存时(分配方法是指针碰撞),会发生堆内存指针指向的冲突问题。而JVM可通过TLAB来减少此类问题产生。
TLAB的全称是Thread Local Allocation Buffer,即线程本地分配缓存区,这是一个线程专用的内存分配区域。
控制开启的JVM参数时-XX:+UseTLAB,默认开启。TLAB默认占Eden区的1%空间。
一个JAVA方法在线程栈中的执行流程
通过javap -c可将java类文件输出成具有可读性的字节码文件。分析文件中的JVM指令可理解Java方法执行。
该文画的图片比较清晰:
JVM虚拟机栈执行原理深入详解|叶湘伦|知乎
本地方法栈(线程私有)
本地方法栈和Java Stack作用类似, 区别是虚拟机栈为执行Java方法服务, 而本地方法栈则为Native方法服务,如果一个VM实现使用C-linkage模型来支持Native调用,那么该栈将会是一个C栈,但HotSpot VM直接就把本地方法栈和虚拟机栈合二为一。
Java堆
Java堆从GC的角度还可以细分为:新生代(Eden区、From Survivor区和To Survivor区)和老年代。
新生代分为:
- Eden区 Java新对象的出生地(如果新创建的对象占用内存很大,则直接分配到老年代)。当Eden区内存不够的时候就会触发MinorGC,对新生代区进行一次垃圾回收。
- ServivorFrom 上一次GC的幸存者,作为这一次GC的被扫描者。
- ServivorTo 保留了一次MinorGC过程中的幸存者。
MinorGC的过程(复制->清空->互换)
MinorGC采用复制算法。
- eden、servicorFrom 复制到ServicorTo,年龄+1 首先,把Eden和ServivorFrom区域中存活的对象复制到ServicorTo区域(如果有对象的年龄以及达到了老年的标准,则赋值到老年代区), 同时把这些对象的年龄+1(如果ServicorTo不够位置了就放到老年区);
- 清空eden、servicorFrom 然后,清空Eden和ServicorFrom中的对象;
- ServicorTo和ServicorFrom互换
老年代
MajorGC采用标记清除算法:首先扫描一次所有老年代,标记出存活的对象,然后回收没有标记的对象。MajorGC的耗时比较长,因为要扫描再回收。 MajorGC会产生内存碎片,为了减少内存损耗,我们一般需要进行合并或者标记出来方便下次直接分配。当老年代也满了装不下的时候,就会抛出OOM(Out of Memory)异常。
方法区/永久代(线程共享)
即我们常说的永久代(Permanent Generation), 用于存储被JVM加载的类信息、常量、静态变量、即时编译器编译后的代码等数据.HotSpotVM把GC分代收集扩展至方法区,即使用Java 堆的永久代来实现方法区, 这样HotSpot的垃圾收集器就可以像管理Java堆一样管理这部分内存, 而不必为方法区开发专门的内存管理器(永久带的内存回收的主要目标是针对常量池的回收和类型的卸载, 因此收益一般很小)。
运行时常量池(Runtime Constant Pool)是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述等信息外, 还有一项信息是常量池(Constant Pool Table),用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。 Java虚拟机对Class文件的每一部分(自然也包括常量池)的格式都有严格的规定,每一个字节用于存储哪种数据都必须符合规范上的要求,这样才会被虚拟机认可、装载和执行。
JAVA8与元数据
为什么用元空间(Metaspace)取代永久代(PermGen)呢?
在Java8中,永久代已经被移除,被一个称为“元数据区”(元空间)的区域所取代。元空间的本质和永久代类似,元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制。类的元数据放入native memory(非paging cache), 字符串池和类的静态变量放入java堆中,这样可以加载多少类的元数据就不再由MaxPermSize控制, 而由系统的实际可用内存空间来控制。
说两个细节:
- PermGen总是有一个固定的最大容量(size)而Metaspace可以是自由增长容量(size)的
- PermGen在开启了CMSClassUnloadingEnabled这一JVM参数并使用CMS垃圾收集器时可以做到类卸载(unload),而metaspace本身有GC机制。
拓展:linux内存管理
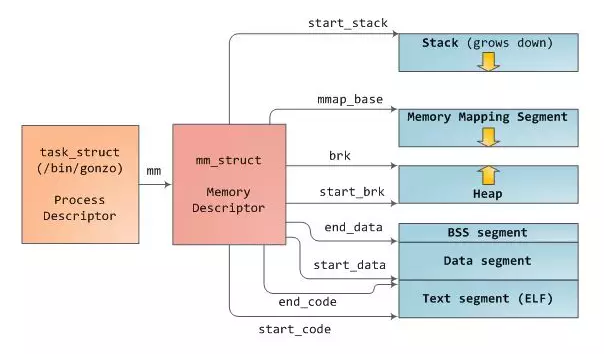 在linux中,每一个进程都被抽象为task_struct结构体,称为进程描述符,存储着进程
在linux中,每一个进程都被抽象为task_struct结构体,称为进程描述符,存储着进程
各方面的信息;例如打开的文件,信号以及内存等等;然后task_struct的一个属性mm_struct管理着进程的所有虚拟内存,称为内存描述符。在mm_struct结构体中,存储着进程各个内存段的开始以及结尾,如上图所示;这个进程使用的物理内存,即常驻内存RSS页数,这个内存使用的虚拟地址空间VSZ页数,还有这个进程虚拟内存区域集合和页表。
从上面这个图可以看出,进程是有代码段Text segment,数据段(已初始化的全局,静态变量),BSS段(未初始化的全局,静态变量),堆,内存映射区以及栈;
每一块虚拟内存区(VMA)都是由一块连续的虚拟地址组成,这些地址从不覆盖。一个vm_area_struct实例描述了一块内存区域,包括这块内存区域的开始以及结尾地址;flags标志决定了这块内存的访问权限和行为;vm_file决定这块内存是由哪个文件映射的,如果没有文件映射,则这块内存为匿名的(anonymous)。上述图中提到的每个内存段,都对应于一个vm_area_struct结构。如下图所示
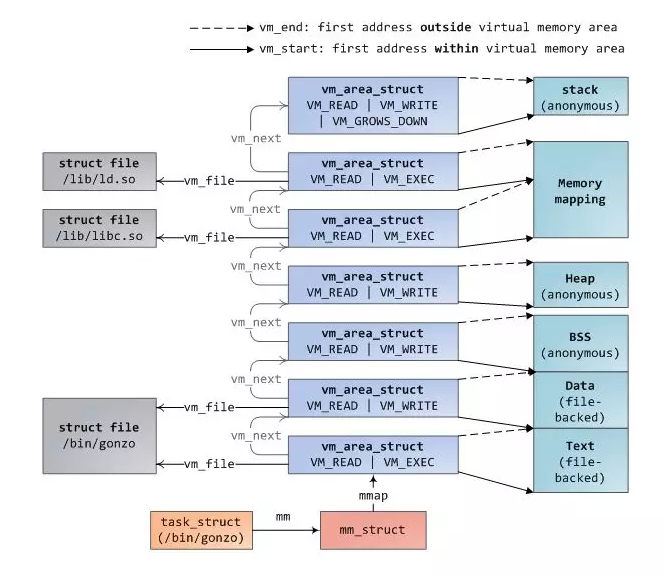
上图即为/bin/gonzo进程的内存布局。程序的二进制文件映射到代码段和数据段,代码段为只读只执行,不可更改;全局以及静态的未初始化的变量映射到BSS段,为匿名映射,堆和栈也是匿名映射,因为没有相应的文件映射;内存映射区可以映射共享库,映射文件以及匿名映射,所以这块内存段可以是文件映射也可以是匿名映射。而且不同的文件,映射到不同的vm_area_struct区。
这些vm_area_struct集合存储在mm_struct中的一个单向链表和红黑树中;当输出/proc/pid/maps文件时,只需要遍历这个链表即可。红黑树主要是为了快速定位到某一个内存块,红黑树的根存储在mm_rb域。
之前介绍过,线性地址需要通过页表才能转换为物理地址。每个进程的内存描述符也保存了这个进程页表指针pgd,每一块虚拟内存页都和页表的某一项对应。
虚拟内存是不存储任何数据的,它只是将地址空间映射到物理内存。物理内存有内核伙伴系统分配,如果一块物理内存没有被映射,就可以被伙伴系统分配给虚拟内存。刚分配的物理内存叶框可能是匿名的,存储进程数据,也可能是也缓存,存储文件或块设备的数据。一块虚拟内存vm_area_struct块是由连续的虚拟内存页组成的,而这些虚拟内存块映射的物理内存却不一定连续,如下图所示:
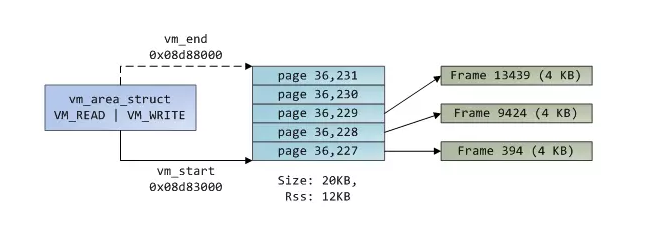
如上图所示,有三个页映射到物理内存,还有两个页没有映射,所以常驻内存RSS为12kb,而虚拟内存大小为20kb。对于有映射到物理内存的三个页的页表项PTE的Present标志设为1,而两个没有映射物理内存的虚拟内存页表项的Present位清除。所以这时访问那两块内存,则会导致异常缺页。
vma就像应用程序和内核的一个契约。当应用程序申请内存或者文件映射时,内核先响应这个请求,分配或更新虚拟内存;但是这些虚拟内存并没有映射到真实的物理内存。而是等到内存访问产生一个内存异常缺页时才真正映射物理内存。即当访问没有映射的虚拟内存时,由于页表项的Present位没有被设置,所以此时会产生一个缺页异常。vma记录和页表项两个在解决内存缺页,释放内存以及内存swap out都起着重要的作用。下面图展示了上述情况:
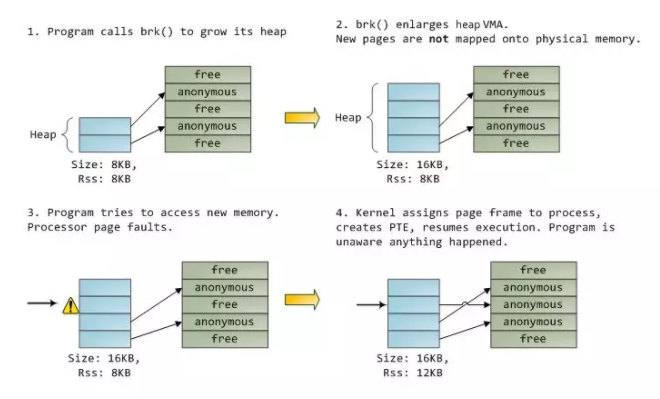
1、一开始堆中只有8kb的内存,而且都已经映射到物理内存;
2、当调用brk()函数扩展堆时,新的页是没有映射到物理内存的,
3、当处理器需要访问一个地址,而且这个地址在上述刚分配的虚拟内存中,这时产生一个缺页异常;
4、这时进程向伙伴系统申请一页的物理内存,映射到那块虚拟内存上,并添加页表项,设置Present位.
自此,这个内存管理暂时就说到这。总结下:
1、Linux进程的内存布局的每个段都是有一个vm_area_struct,而这个实例是由连续的虚拟内存地址组成;
2、当请求内存时,先是扩展vm_area_struct或者新分配一个vm_area_struct,但是并不映射物理内存,只有等到访问这块内存时,产生缺页异常,内核才分配物理内存。
这里再列两篇文章: 浅谈Linux内存管理|lecury|zhihu linux 内存看一篇就够了|mfdalf
GC
垃圾收集器介绍
Serial垃圾收集器(单线程、复制算法)
Serial(英文连续)是最基本垃圾收集器,使用复制算法,曾经是JDK1.3.1 之前新生代唯一的垃圾 收集器。Serial 是一个单线程的收集器,它不但只会使用一个CPU 或一条线程去完成垃圾收集工 作,并且在进行垃圾收集的同时,必须暂停其他所有的工作线程,直到垃圾收集结束。 Serial 垃圾收集器虽然在收集垃圾过程中需要暂停所有其他的工作线程,但是它简单高效,对于限 定单个CPU 环境来说,没有线程交互的开销,可以获得最高的单线程垃圾收集效率,因此Serial 垃圾收集器依然是java 虚拟机运行在Client 模式下默认的新生代垃圾收集器。
ParNew垃圾收集器(Serial+多线程)
ParNew 垃圾收集器其实是Serial 收集器的多线程版本,也使用复制算法,除了使用多线程进行垃 圾收集之外,其余的行为和Serial 收集器完全一样,ParNew 垃圾收集器在垃圾收集过程中同样也 要暂停所有其他的工作线程。
ParNew 收集器默认开启和CPU 数目相同的线程数,可以通过-XX:ParallelGCThreads 参数来限 制垃圾收集器的线程数。【Parallel:平行的】 ParNew虽然是除了多线程外和Serial 收集器几乎完全一样,但是ParNew垃圾收集器是很多java 虚拟机运行在Server 模式下新生代的默认垃圾收集器。
Parallel Scavenge收集器(多线程复制算法、高效)
Parallel Scavenge 收集器也是一个新生代垃圾收集器,同样使用复制算法,也是一个多线程的垃 圾收集器,它重点关注的是程序达到一个可控制的吞吐量(Thoughput,CPU 用于运行用户代码 的时间/CPU 总消耗时间,即吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)), 高吞吐量可以最高效率地利用CPU 时间,尽快地完成程序的运算任务,主要适用于在后台运算而 不需要太多交互的任务。自适应调节策略也是ParallelScavenge 收集器与ParNew 收集器的一个 重要区别。
Serial Old收集器(单线程标记整理算法)
Serial Old 是Serial 垃圾收集器年老代版本,它同样是个单线程的收集器,使用标记-整理算法, 这个收集器也主要是运行在Client 默认的java 虚拟机默认的年老代垃圾收集器。 在Server 模式下,主要有两个用途:
- 在JDK1.5 之前版本中与新生代的Parallel Scavenge 收集器搭配使用。
- 作为年老代中使用CMS 收集器的后备垃圾收集方案。
新生代Serial 与年老代Serial Old 搭配垃圾收集过程图:
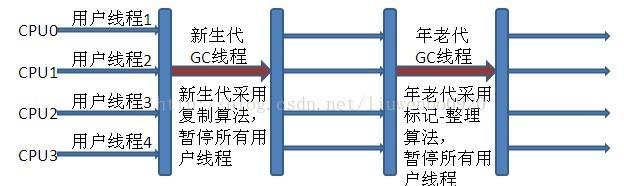
新生代Parallel Scavenge 收集器与ParNew 收集器工作原理类似,都是多线程的收集器,都使
用的是复制算法,在垃圾收集过程中都需要暂停所有的工作线程。新生代Parallel
Scavenge/ParNew 与年老代Serial Old 搭配垃圾收集过程图:
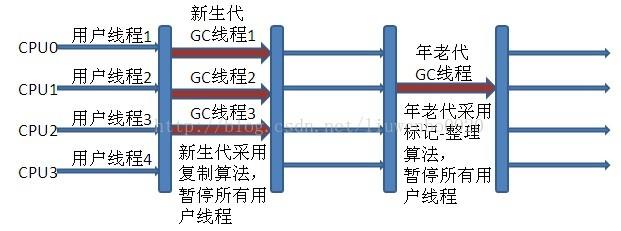
Parallel Old收集器(多线程标记整理算法)
Parallel Old 收集器是Parallel Scavenge 的年老代版本,使用多线程的标记-整理算法,在JDK1.6 才开始提供。 在JDK1.6 之前,新生代使用ParallelScavenge 收集器只能搭配年老代的Serial Old 收集器,只 能保证新生代的吞吐量优先,无法保证整体的吞吐量,Parallel Old 正是为了在年老代同样提供吞 吐量优先的垃圾收集器,如果系统对吞吐量要求比较高,可以优先考虑新生代Parallel Scavenge 和年老代Parallel Old 收集器的搭配策略。
CMS收集器(多线程标记清除算法)
Concurrent mark sweep(CMS)收集器是一种年老代垃圾收集器,其最主要目标是获取最短垃圾 回收停顿时间,和其他年老代使用标记-整理算法不同,它使用多线程的标记-清除算法。 最短的垃圾收集停顿时间可以为交互比较高的程序提高用户体验。 CMS 工作机制相比其他的垃圾收集器来说更复杂,整个过程分为以下4 个阶段:
- 初始标记 只是标记一下GC Roots 能直接关联的对象,速度很快,仍然需要暂停所有的工作线程。
- 并发标记 进行GC Roots 跟踪的过程,和用户线程一起工作,不需要暂停工作线程。
- 重新标记 为了修正在并发标记期间,因用户程序继续运行而导致标记产生变动的那一部分对象的标记 记录,仍然需要暂停所有的工作线程。
- 并发清除
清除GC Roots 不可达对象,和用户线程一起工作,不需要暂停工作线程。由于耗时最长的并
发标记和并发清除过程中,垃圾收集线程可以和用户现在一起并发工作,所以总体上来看
CMS 收集器的内存回收和用户线程是一起并发地执行。
CMS 收集器工作过程: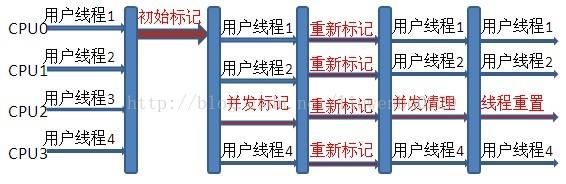
G1收集器
Garbage first 垃圾收集器是目前垃圾收集器理论发展的最前沿成果,相比与CMS 收集器,G1 收 集器两个最突出的改进是:
- 基于标记-整理算法,不产生内存碎片。
- 可以非常精确控制停顿时间,在不牺牲吞吐量前提下,实现低停顿垃圾回收。
G1 收集器避免全区域垃圾收集,它把堆内存划分为大小固定的几个独立区域,并且跟踪这些区域 的垃圾收集进度,同时在后台维护一个优先级列表,每次根据所允许的收集时间,优先回收垃圾 最多的区域。区域划分和优先级区域回收机制,确保G1 收集器可以在有限时间获得最高的垃圾收 集效率。
JAVA 四种引用类型
- 强引用
在Java 中最常见的就是强引用,把一个对象赋给一个引用变量,这个引用变量就是一个强引 用。当一个对象被强引用变量引用时,它处于可达状态,它是不可能被垃圾回收机制回收的,即 使该对象以后永远都不会被用到JVM也不会回收。因此强引用是造成Java 内存泄漏的主要原因之一。 - 软引用
软引用需要用SoftReference 类来实现,对于只有软引用的对象来说,当系统内存足够时它 不会被回收,当系统内存空间不足时它会被回收。软引用通常用在对内存敏感的程序中。(OOM前) - 弱引用
弱引用需要用WeakReference 类来实现,它比软引用的生存期更短,对于只有弱引用的对象 来说,只要垃圾回收机制一运行,不管JVM 的内存空间是否足够,总会回收该对象占用的内存。 - 虚引用
虚引用需要PhantomReference 类来实现,它不能单独使用,必须和引用队列联合使用。虚 引用的主要作用是跟踪对象被垃圾回收的状态。
线程
HotspotJVM 后台运行的系统线程主要有下面几个:
| 线程类型 | 描述 |
|---|---|
| 虚拟机线程(VM thread) | 这个线程等待JVM到达安全点操作出现。这些操作必须要在独立的线程里执行,因为当堆修改无法进行时,线程都需要JVM 位于安全点。这些操作的类型有:stop-the-world 垃圾回收、线程栈dump、线程暂停、线程偏向锁(biased locking)解除。 |
| 周期性任务线程 | 这线程负责定时器事件(也就是中断),用来调度周期性操作的执行。 |
| GC 线程 | 这些线程支持JVM 中不同的垃圾回收活动。 |
| 编译器线程 | 这些线程在运行时将字节码动态编译成本地平台相关的机器码。 |
| 信号分发线程 | 这个线程接收发送到JVM的信号并调用适当的JVM方法处理。 |
volatile
https://www.cnblogs.com/simpleDi/p/11517150.html
JVM参数调优
参考一些业界成熟的中间件的JVM参数是一个不错的选择。
Cassandra用到的JVM参数及其调优指南:Amy's Cassandra 2.1 tuning guide
这个是唯品会的一个工具的JVM参数,同时也是唯品会内部用到的JVM参数:vipshop/vjtools|github
JDK
线程池的参数配置
- 线程池管理器:用于创建并管理线程池
- 工作线程:线程池中的线程
- 任务接口:每个任务必须实现的接口,用于工作线程调度其运行
- 任务队列:用于存放待处理的任务,提供一种缓冲机制
Java 中的线程池是通过 Executor 框架实现的,该框架中用到了 Executor,Executors,ExecutorService,ThreadPoolExecutor ,Callable 和 Future、FutureTask 这几个类。
ThreadPoolExecutor 的构造方法如下:
public ThreadPoolExecutor( int corePoolSize,int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue ) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), defaultHandler);
}- corePoolSize:指定了线程池中的线程数量。
- maximumPoolSize:指定了线程池中的最大线程数量。
- keepAliveTime:当前线程池数量超过corePoolSize时,多余的空闲线程的存活时间,即多次时间内会被销毁。
- unit:keepAliveTime 的单位。
- workQueue:任务队列,被提交但尚未被执行的任务。
- threadFactory:线程工厂,用于创建线程,一般用默认的即可。
- handler:拒绝策略,当任务太多来不及处理,如何拒绝任务。
一致性算法
Paxos
Paxos 算法解决的问题是一个分布式系统如何就某个值(决议)达成一致。一个典型的场景是, 在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点执行相同的操作序列,那么 他们最后能得到一个一致的状态。为保证每个节点执行相同的命令序列,需要在每一条指令上执 行一个“一致性算法”以保证每个节点看到的指令一致。zookeeper 使用的 zab 算法是该算法的 一个实现。 在 Paxos 算法中,有三种角色:Proposer,Acceptor,Learners
Paxos 三种角色:Proposer、Acceptor、learner
- Proposer 只要Proposer发的提案被半数以上Acceptor接受,Proposer就认为该提案里的value被选定了
- Acceptor 只要 Acceptor 接受了某个提案,Acceptor 就认为该提案里的 value 被选定了。
- Learner Acceptor 告诉 Learner 哪个 value 被选定,Learner 就认为那个 value 被选定
在paxos算法的具体使用场景中,被选出的值最终会应用到复制状态机,也就是在应用层生效。learner正是负责感知被选出的决议并最终促使该决议apply到复制状态机。在具体的实践中,每个物理节点会同时担任多个角色
- Leader:同时担任proposer、acceptor和learner
- Follower:同时担任acceptor和learner
Paxos 算法分为两个阶段。具体如下:
- 阶段一(准 leader 确定 ):
- (a) Proposer 选择一个提案编号 N,然后向半数以上的 Acceptor 发送编号为 N 的 Prepare 请求。
- (b) 如果一个 Acceptor 收到一个编号为 N 的 Prepare 请求,且 N 大于该 Acceptor 已经响应过的 所有 Prepare 请求的编号,那么它就会将它已经接受过的编号最大的提案(如果有的话)作为响 应反馈给 Proposer,同时该 Acceptor 承诺不再接受任何编号小于 N 的提案。
- 阶段二(leader 确认):
- (a) 如果 Proposer 收到半数以上 Acceptor 对其发出的编号为 N 的 Prepare 请求的响应,那么它 就会发送一个针对[N,V]提案的 Accept 请求给半数以上的 Acceptor。注意:V 就是收到的响应中 编号最大的提案的 value,如果响应中不包含任何提案,那么 V 就由 Proposer 自己决定。
- (b) 如果 Acceptor 收到一个针对编号为 N 的提案的 Accept 请求,只要该 Acceptor 没有对编号 大于 N 的 Prepare 请求做出过响应,它就接受该提案。
Zab
ZAB( ZooKeeper Atomic Broadcast , ZooKeeper 原子消息广播协议)协议包括两种基本的模 式:崩溃恢复和消息广播
- 当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断崩溃退出与重启等异常情 况时,ZAB 就会进入恢复模式并选举产生新的 Leader 服务器。
- 当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该 Leader 服务器完成了 状态同步之后,ZAB 协议就会退出崩溃恢复模式,进入消息广播模式。
- 当有新的服务器加入到集群中去,如果此时集群中已经存在一个 Leader 服务器在负责进行消 息广播,那么新加入的服务器会自动进入数据恢复模式,找到 Leader 服务器,并与其进行数 据同步,然后一起参与到消息广播流程中去。
以上其实大致经历了三个步骤:
- 崩溃恢复:主要就是 Leader 选举过程
- 数据同步:Leader 服务器与其他服务器进行数据同步
- 消息广播:Leader 服务器将数据发送给其他服务器
说明:zookeeper 章节对该协议有详细描述
Raft
与 Paxos 不同 Raft 强调的是易懂(Understandability),Raft 和 Paxos 一样只要保证 n/2+1 节 点正常就能够提供服务;raft 把算法流程分为三个子问题:选举(Leader election)、日志复制 (Log replication)、安全性(Safety)三个子问题。
角色
Raft 把集群中的节点分为三种状态:Leader、 Follower 、Candidate,理所当然每种状态负 责的任务也是不一样的,Raft 运行时提供服务的时候只存在 Leader 与 Follower 两种状态;
- Leader(领导者-日志管理) 负责日志的同步管理,处理来自客户端的请求,与 Follower 保持这 heartBeat 的联系;
- Follower(追随者-日志同步) 刚启动时所有节点为Follower状态,响应Leader的日志同步请求,响应Candidate的请求, 把请求到 Follower 的事务转发给 Leader;
- Candidate(候选者-负责选票) 负责选举投票,Raft 刚启动时由一个节点从 Follower 转为 Candidate 发起选举,选举出 Leader 后从 Candidate 转为 Leader 状态;
Term(任期)
在 Raft 中使用了一个可以理解为周期(第几届、任期)的概念,用 Term 作为一个周期,每 个 Term 都是一个连续递增的编号,每一轮选举都是一个 Term 周期,在一个 Term 中只能产生一 个 Leader;当某节点收到的请求中 Term 比当前 Term 小时则拒绝该请求。
选举(Election)
选举定时器
Raft 的选举由定时器来触发,每个节点的选举定时器时间都是不一样的,开始时状态都为 Follower 某个节点定时器触发选举后 Term 递增,状态由 Follower 转为 Candidate,向其他节点 发起 RequestVote RPC 请求,这时候有三种可能的情况发生:
- 该 RequestVote 请求接收到 n/2+1(过半数)个节点的投票,从 Candidate 转为 Leader, 向其他节点发送 heartBeat 以保持 Leader 的正常运转。
- 在此期间如果收到其他节点发送过来的 AppendEntries RPC 请求,如该节点的 Term 大 则当前节点转为 Follower,否则保持 Candidate 拒绝该请求。
- Election timeout 发生则 Term 递增,重新发起选举
在一个 Term 期间每个节点只能投票一次,所以当有多个 Candidate 存在时就会出现每个 Candidate 发起的选举都存在接收到的投票数都不过半的问题,这时每个 Candidate 都将 Term 递增、重启定时器并重新发起选举,由于每个节点中定时器的时间都是随机的,所以就不会多次 存在有多个 Candidate 同时发起投票的问题。
在 Raft 中当接收到客户端的日志(事务请求)后先把该日志追加到本地的 Log 中,然后通过 heartbeat 把该 Entry 同步给其他 Follower,Follower 接收到日志后记录日志然后向 Leader 发送 ACK,当 Leader 收到大多数(n/2+1)Follower 的 ACK 信息后将该日志设置为已提交并追加到 本地磁盘中,通知客户端并在下个 heartbeat 中 Leader 将通知所有的 Follower 将该日志存储在 自己的本地磁盘中。
安全性(Safety)
安全性是用于保证每个节点都执行相同序列的安全机制如当某个 Follower 在当前 Leader commit Log 时变得不可用了,稍后可能该 Follower 又会倍选举为 Leader,这时新 Leader 可能会用新的 Log 覆盖先前已 committed 的 Log,这就是导致节点执行不同序列;Safety 就是用于保证选举出 来的 Leader 一定包含先前 commited Log 的机制;
- 选举安全性(Election Safety):每个 Term 只能选举出一个 Leader
- Leader 完整性(Leader Completeness):这里所说的完整性是指 Leader 日志的完整性, Raft 在选举阶段就使用 Term 的判断用于保证完整性:当请求投票的该 Candidate 的 Term 较大 或 Term 相同 Index 更大则投票,该节点将容易变成 leader。
raft 协议和 zab 协议区别
相同点
- 采用 quorum 来确定整个系统的一致性,这个 quorum 一般实现是集群中半数以上的服务器,
- zookeeper 里还提供了带权重的 quorum 实现
- 都由 leader 来发起写操作
- 都采用心跳检测存活性
- leader election 都采用先到先得的投票方式
不同点
- zab 用的是 epoch 和 count 的组合来唯一表示一个值, 而 raft 用的是 term 和 index
- zab 的 follower 在投票给一个 leader 之前必须和 leader 的日志达成一致,而 raft 的 follower 则简单地说是谁的 term 高就投票给谁
- raft 协议的心跳是从 leader 到 follower, 而 zab 协议则相反
- raft 协议数据只有单向地从 leader 到 follower(成为 leader 的条件之一就是拥有最新的 log), 而 zab 协议在 discovery 阶段, 一个 prospective leader 需要将自己的 log 更新为 quorum 里面 最新的 log,然后才好在 synchronization 阶段将 quorum 里的其他机器的 log 都同步到一致.
NWR
Gossip
Gossip 算法又被称为反熵(Anti-Entropy),熵是物理学上的一个概念,代表杂乱无章,而反熵 就是在杂乱无章中寻求一致,这充分说明了 Gossip 的特点:在一个有界网络中,每个节点都随机 地与其他节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一致。每个节点可 能知道所有其他节点,也可能仅知道几个邻居节点,只要这些节可以通过网络连通,最终他们的 状态都是一致的,
当然这也是疫情传播的特点。
Zookeeper
Zookeeper 是一个分布式协调服务,可用于服务发现,分布式锁,分布式领导选举,配置管理等。 Zookeeper 提供了一个类似于 Linux 文件系统的树形结构(可认为是轻量级的内存文件系统,但 只适合存少量信息,完全不适合存储大量文件或者大文件),同时提供了对于每个节点的监控与 通知机制。
Zookeeper 角色
Zookeeper 集群是一个基于主从复制的高可用集群,每个服务器承担如下三种角色中的一种
leader
- 一个 Zookeeper 集群同一时间只会有一个实际工作的 Leader,它会发起并维护与各 Follwer 及 Observer 间的心跳。
- 所有的写操作必须要通过 Leader 完成再由 Leader 将写操作广播给其它服务器。只要有超过 半数节点(不包括 observeer 节点)写入成功,该写请求就会被提交(类 2PC 协议)。
Follower
- 一个 Zookeeper 集群可能同时存在多个 Follower,它会响应 Leader 的心跳,
- Follower 可直接处理并返回客户端的读请求,同时会将写请求转发给 Leader 处理,
- 并且负责在 Leader 处理写请求时对请求进行投票。
Observer
角色与 Follower 类似,但是无投票权。Zookeeper 需保证高可用和强一致性,为了支持更多的客 户端,需要增加更多 Server;Server 增多,投票阶段延迟增大,影响性能;引入 Observer, Observer 不参与投票; Observers 接受客户端的连接,并将写请求转发给 leader 节点; 加入更 多 Observer 节点,提高伸缩性,同时不影响吞吐率。
事务编号
Zxid(事务请求计数器+ epoch) 在 ZAB ( ZooKeeper Atomic Broadcast , ZooKeeper 原子消息广播协议) 协议的事务编号 Zxid 设计中,Zxid 是一个 64 位的数字,其中低 32 位是一个简单的单调递增的计数器,针对客户端每 一个事务请求,计数器加 1;而高 32 位则代表 Leader 周期 epoch 的编号,每个当选产生一个新 的 Leader 服务器,就会从这个 Leader 服务器上取出其本地日志中最大事务的 ZXID,并从中读取 epoch 值,然后加 1,以此作为新的 epoch,并将低 32 位从 0 开始计数。 Zxid(Transaction id)类似于 RDBMS 中的事务 ID,用于标识一次更新操作的 Proposal(提议) ID。为了保证顺序性,该 zkid 必须单调递增。
epoch
epoch:可以理解为当前集群所处的年代或者周期,每个 leader 就像皇帝,都有自己的年号,所 以每次改朝换代,leader 变更之后,都会在前一个年代的基础上加 1。这样就算旧的 leader 崩溃 恢复之后,也没有人听他的了,因为 follower 只听从当前年代的 leader 的命令。
Zab 协议有两种模式-恢复模式(选主)、广播模式(同步)
Zab 协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导 者崩溃后,Zab 就进入了恢复模式,当领导者被选举出来,且大多数 Server 完成了和 leader 的状 态同步以后,恢复模式就结束了。状态同步保证了 leader 和 Server 具有相同的系统状态。
ZAB 协议 4 阶段
- Leader election(选举阶段-选出准 Leader)
Leader election(选举阶段):节点在一开始都处于选举阶段,只要有一个节点得到超半数 节点的票数,它就可以当选准 leader。只有到达 广播阶段(broadcast) 准 leader 才会成 为真正的 leader。这一阶段的目的是就是为了选出一个准 leader,然后进入下一个阶段 - Discovery(发现阶段-接受提议、生成 epoch、接受 epoch)
Discovery(发现阶段):在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。这个一阶段的主要目的是发现当前大多数节点接收的最新提议,并且 准 leader 生成新的 epoch,让 followers 接受,更新它们的 accepted Epoch 一个 follower 只会连接一个 leader,如果有一个节点 f 认为另一个 follower p 是 leader,f 在尝试连接 p 时会被拒绝,f 被拒绝之后,就会进入重新选举阶段。 - Synchronization(同步阶段-同步 follower 副本)
Synchronization(同步阶段):同步阶段主要是利用 leader 前一阶段获得的最新提议历史, 同步集群中所有的副本。只有当 大多数节点都同步完成,准 leader 才会成为真正的 leader。 follower 只会接收 zxid 比自己的 lastZxid 大的提议。 - Broadcast(广播阶段-leader 消息广播)
Broadcast(广播阶段):到了这个阶段,Zookeeper 集群才能正式对外提供事务服务, 并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
ZAB 提交事务并不像 2PC 一样需要全部 follower 都 ACK,只需要得到超过半数的节点的ACK就可以了。
ZAB 协议 JAVA 实现(FLE-发现阶段和同步合并为 Recovery Phase(恢复阶段))
协议的 Java 版本实现跟上面的定义有些不同,选举阶段使用的是 Fast Leader Election(FLE),
它包含了 选举的发现职责。因为 FLE 会选举拥有最新提议历史的节点作为 leader,这样就省去了
发现最新提议的步骤。实际的实现将 发现阶段 和 同步合并为 Recovery Phase(恢复阶段)。所
以,ZAB 的实现只有三个阶段:Fast Leader Election;Recovery Phase;Broadcast Phase。
投票机制
每个 sever 首先给自己投票,然后用自己的选票和其他 sever 选票对比,权重大的胜出,使用权 重较大的更新自身选票箱。具体选举过程如下:
- 每个 Server 启动以后都询问其它的 Server 它要投票给谁。对于其他 server 的询问, server 每次根据自己的状态都回复自己推荐的 leader 的 id 和上一次处理事务的 zxid(系 统启动时每个 server 都会推荐自己)
- 收到所有 Server 回复以后,就计算出 zxid 最大的哪个 Server,并将这个 Server 相关信 息设置成下一次要投票的 Server。
- 计算这过程中获得票数最多的的 sever 为获胜者,如果获胜者的票数超过半数,则改 server 被选为 leader。否则,继续这个过程,直到 leader 被选举出来
- leader 就会开始等待 server 连接
- Follower 连接 leader,将最大的 zxid 发送给 leader
- Leader 根据 follower 的 zxid 确定同步点,至此选举阶段完成。
- 选举阶段完成 Leader 同步后通知 follower 已经成为 uptodate 状态
- Follower 收到 uptodate 消息后,又可以重新接受 client 的请求进行服务了
目前有 5 台服务器,每台服务器均没有数据,它们的编号分别是 1,2,3,4,5,按编号依次启动,它们 的选择举过程如下:
- 服务器 1 启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反 馈信息,服务器 1 的状态一直属于 Looking。
- 服务器 2 启动,给自己投票,同时与之前启动的服务器 1 交换结果,由于服务器 2 的编号 大所以服务器 2 胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是 LOOKING。
- 服务器 3 启动,给自己投票,同时与之前启动的服务器 1,2 交换信息,由于服务器 3 的编 号最大所以服务器 3 胜出,此时投票数正好大于半数,所以服务器 3 成为领导者,服务器 1,2 成为小弟。
- 服务器 4 启动,给自己投票,同时与之前启动的服务器 1,2,3 交换信息,尽管服务器 4 的 编号大,但之前服务器 3 已经胜出,所以服务器 4 只能成为小弟。
- 服务器 5 启动,后面的逻辑同服务器 4 成为小弟。
Zookeeper 工作原理(原子广播)
- Zookeeper 的核心是原子广播,这个机制保证了各个 server 之间的同步。实现这个机制 的协议叫做 Zab 协议。Zab 协议有两种模式,它们分别是恢复模式和广播模式。
- 当服务启动或者在领导者崩溃后,Zab 就进入了恢复模式,当领导者被选举出来,且大多 数 server 的完成了和 leader 的状态同步以后,恢复模式就结束了。
- 状态同步保证了 leader 和 server 具有相同的系统状态
- 一旦 leader 已经和多数的 follower 进行了状态同步后,他就可以开始广播消息了,即进 入广播状态。这时候当一个 server 加入 zookeeper 服务中,它会在恢复模式下启动,发 现 leader,并和 leader 进行状态同步。待到同步结束,它也参与消息广播。Zookeeper 服务一直维持在 Broadcast 状态,直到 leader 崩溃了或者 leader 失去了大部分的 followers 支持。
- 广播模式需要保证 proposal 被按顺序处理,因此 zk 采用了递增的事务 id 号(zxid)来保 证。所有的提议(proposal)都在被提出的时候加上了 zxid。
- 实现中 zxid 是一个 64 为的数字,它高 32 位是 epoch 用来标识 leader 关系是否改变, 每次一个 leader 被选出来,它都会有一个新的 epoch。低 32 位是个递增计数。
- 当 leader 崩溃或者 leader 失去大多数的 follower,这时候 zk 进入恢复模式,恢复模式 需要重新选举出一个新的 leader,让所有的 server 都恢复到一个正确的状态。
Znode
Znode 有四种形式的目录节点
- PERSISTENT:持久的节点。
- EPHEMERAL:暂时的节点。
- PERSISTENT_SEQUENTIAL:持久化顺序编号目录节点。
- EPHEMERAL_SEQUENTIAL:暂时化顺序编号目录节点。
脑裂
https://www.cnblogs.com/kevingrace/p/12433503.html
网络
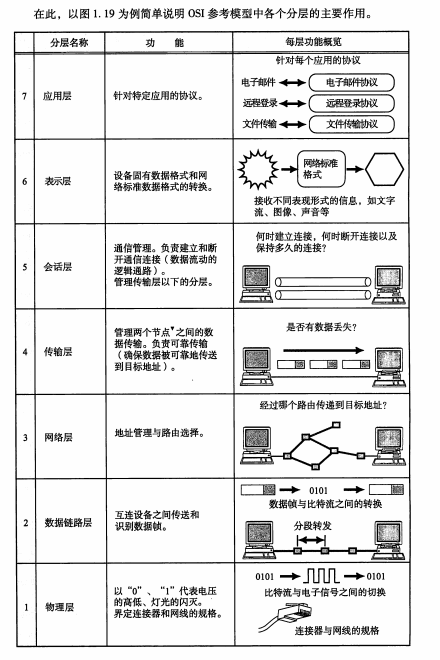
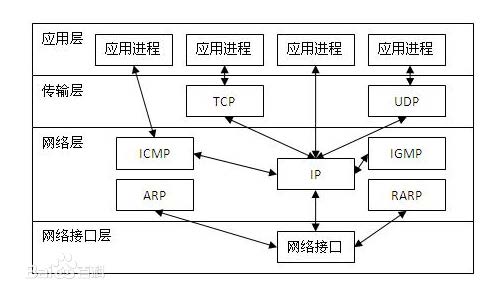
网络7 层架构
7 层模型主要包括:
- 物理层:主要定义物理设备标准,如网线的接口类型、光纤的接口类型、各种传输介质的传输速率 等。它的主要作用是传输比特流(就是由1、0 转化为电流强弱来进行传输,到达目的地后在转化为 1、0,也就是我们常说的模数转换与数模转换)。这一层的数据叫做比特。
- 数据链路层:主要将从物理层接收的数据进行MAC 地址(网卡的地址)的封装与解封装。常把这 一层的数据叫做帧。在这一层工作的设备是交换机,数据通过交换机来传输。
- 网络层:主要将从下层接收到的数据进行IP 地址(例192.168.0.1)的封装与解封装。在这一层工 作的设备是路由器,常把这一层的数据叫做数据包。
- 传输层:定义了一些传输数据的协议和端口号(WWW 端口80 等),如:TCP(传输控制协议, 传输效率低,可靠性强,用于传输可靠性要求高,数据量大的数据),UDP(用户数据报协议, 与TCP 特性恰恰相反,用于传输可靠性要求不高,数据量小的数据,如QQ 聊天数据就是通过这 种方式传输的)。 主要是将从下层接收的数据进行分段进行传输,到达目的地址后在进行重组。 常常把这一层数据叫做段。
- 会话层:通过传输层(端口号:传输端口与接收端口)建立数据传输的通路。主要在你的系统之间 发起会话或或者接受会话请求(设备之间需要互相认识可以是IP 也可以是MAC 或者是主机名)
- 表示层:主要是进行对接收的数据进行解释、加密与解密、压缩与解压缩等(也就是把计算机能够 识别的东西转换成人能够能识别的东西(如图片、声音等))
- 应用层 主要是一些终端的应用,比如说FTP(各种文件下载),WEB(IE 浏览),QQ之类的(你 就把它理解成我们在电脑屏幕上可以看到的东西.就 是终端应用)。

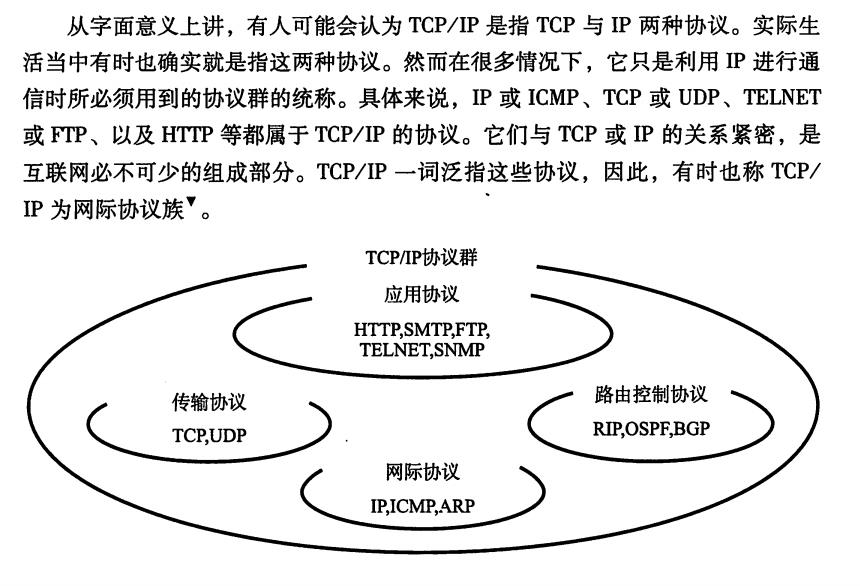
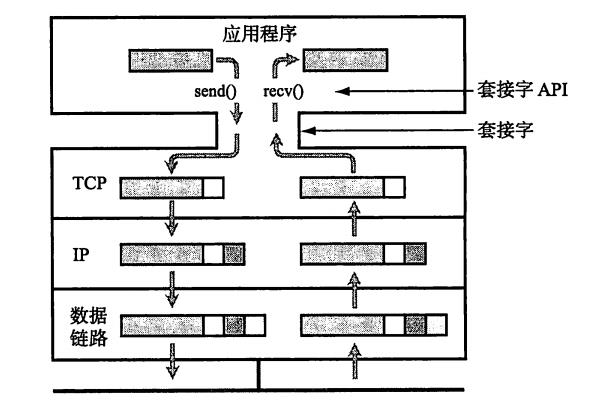
TCP/IP
套接字(socket)
应用在使用TCP或UDP时,会用到操作系统提供的类库。这种类库一般被称为API (Application Programming Interface,应用编程接口)。 使用TCP或UDP通信时,又会广泛使用到套接字(socket)的API0 套接字原本是由BSD UNIX开发的,但是后被移植到了Windows的Winsock 以及嵌入式操作系统中。 应用程序利用套接字,可以设笠对端的IP地址、端口号,并实现数 据的发送与接收。
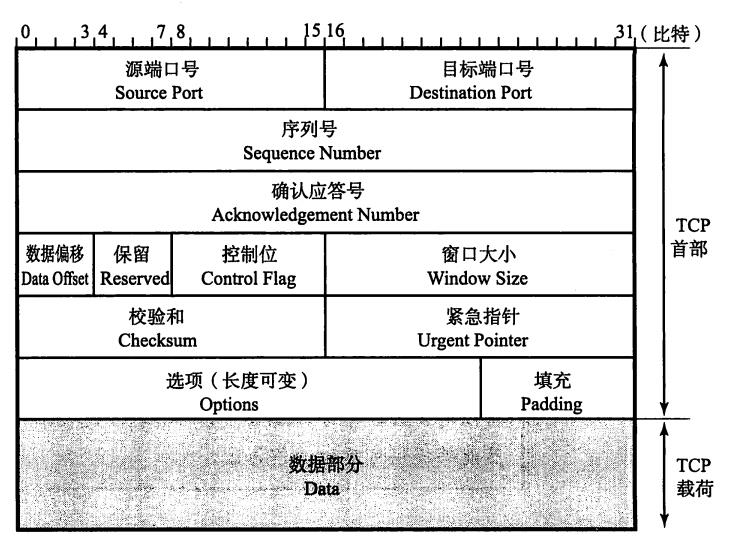
数据包说明
另外, TCP中没有表示包长度和数据长度的字段。可由IP层获知TCP的包长 由TCP的包长可知数据的长度。
说明:
- 源端口号(Source Port) 表示发送端端口号,字段长16位。
- 目标端口号(Destination Port) 表示接收端端口号,字段长度16位。
- 序列号(SequenceNumber) 字段长32位。序列号(有时也叫序号)是指发送数据的位置。每发送一次 数据,就累加一次该数据字节数的大小。 序列号不会从0或1开始,而是在建立连接时由计算机生成的随机数作为其 初始值, 通过SYN包传给接收端主机。 然后再将每转发过去的字节数累加到初始 值上表示数据的位置。 此外, 在建立连接和断开连接时发送的SYN包和FIN包虽 然并不携带数据,但是也会作为一个字节增加对应的序列号。
- 圈确认应答号(Acknowledgement Number) 确认应答号字段长度32位。是指下一次应该收到的数据的序列号。 实际上, 它是指已收到确认应答号减一为止的数据。发送端收到这个确认应答以后可以认为在这个序号以前的数据都已经被正常接收。
- 数据偏移(Data Offset) 该字段表示TCP所传输的数据部分应该从TCP包的哪个位开始计算, 当然也可以把它看作TCP首部的长度。 该字段长4位, 单位为4字节(即32位) 。不包括选项字段的话, 如图TCP的首部为20字节长, 因此数据偏移字段可以设置为5。反之, 如果该字段的值为5, 那说明从TCP包的最一开始到20字节为止都是TCP首部, 余下的部分为TCP数据。
- 保留(Reserved) 该字段主要是为了以后扩展时使用,其长度为4位。 一般设置为0,但即使 收到的包在该字段不为0,此包也不会被丢弃”。
- 控制位(Control Flag) 字段长为8位, 每一位从左至右分别为CWR、ECE、URG、ACK、PSH、 RST、SYN、FIN。这些控制标志也叫做控制位。
当它们对应位上的值为1时, 具体含义如下。
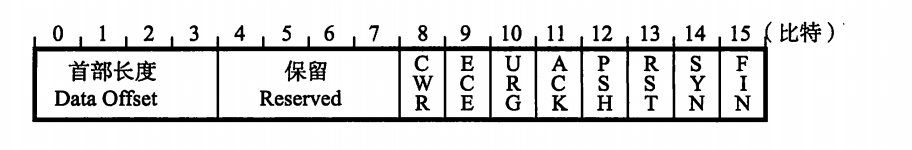
- CWR(Congestion Window Reduced) CWR标志"与后面的ECE标志都用于IP首部的ECN字段。ECE标志为1 时,则通知对方已将拥塞窗口缩小。
- ECE(ECN-Echo) ECE标志"表示ECN-Echo。置为1会通知通信对方, 从对方到这边的网 络有拥塞。在收到数据包的IP首部中ECN为1时将TCP首部中的ECE设 置为1。
- URG(Urgent Flag) 该位为1时,表示包中有需要紧急处理的数据。对于需要紧急处理的数据,会在后面的紧急指针中再进行解释。
- ACK(Acknowledgement Flag) 该位为1时, 确认应答的字段变为有效。TCP规定除了最初建立连接时的 SYN包之外该位必须设置为1。
- PSH(Push Flag) 该位为1时, 表示需要将受到的数据立刻传给上层应用协议。PSH为0 时,则不需要立即传而是先进行缓存。
- RST(Reset Flag) 该位为1时表示TCP连接中出现异常必须强制断开连接。例如,一个没有被使用的端口即使发来连接请求,也无法进行通信。此时就可以返回一个 RST设置为1的包。此外, 程序宕掉或切断电源等原因导致主机重启的情况下, 由于所有的连接信息将全部被初始化, 所以原有的TCP通信也将不能继续进行。 这种情况下, 如果通信对方发送一个设置为1的RST包, 就 会使通信强制断开连接。
- SYN(Synchronize Flag) 用于建立连接。SYN为1表示希望建立连接, 并在其序列号的字段进行序 列号初始值的设定”。
- FIN(Fin Flag) 该位为1时,表示今后不会再有数据发送,希望断开连接。当通信结束希望断开连接时, 通信双方的主机之间就可以相互交换FIN位置为1的TCP段。 每个主机又对对方的FIN包进行确认应答以后就可以断开连接。不过, 主机收到FIN设置为1的TCP段以后不必马上回复一个FIN包, 而是可以等到缓冲区中的所有数据都因已成功发送而被自动删除之后再发。
- 窗口大小(Window Size) 该字段长为16位。用于通知从相同TCP首部的确认应答号所指位置开始能 够接收的数据大小(8位字节) 。 TCP不允许发送超过此处所示大小的数据。不过,如果窗口为0,则表示可以发送窗口探测,以了解最新的窗口大小。但这个数据必须是1个字节。
- 校验和(Checksum)
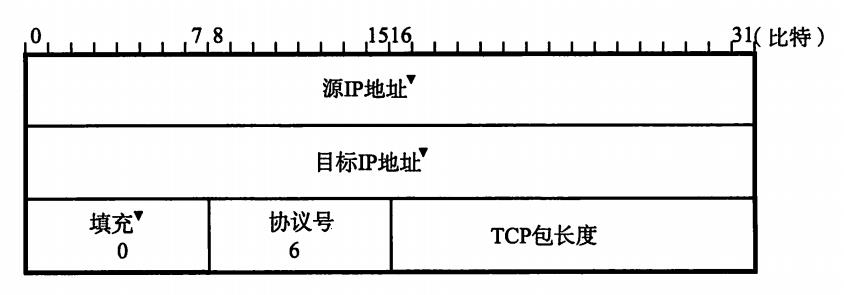
TCP的校验和与UDP相似, 区别在于TCP的校验和无法关闭。 TCP和UDP一样在计算校验和的时候使用TCP伪首部。这个伪首部如图。为了让其全长为16位的整数倍,需要在数据部分的最后填充0。 首先将TCP校验和字段设置为0。然后以16位为单位进行1的补码和计算,再将它们总和的1的补码和放人校验和字段。
接收端在收到TCP数据段以后,从IP首部获取IP地址信息构造TCP伪首部,再进行校验和计算。 由于校验和字段里保存着除本字段以外其他部分的和的补码值,因此如果计算校验和字段在内的所有数据的16位和以后, 得出的结果是 “16位全部为1”说明所收到的数据是正确的。 - 紧急指针(Urgent Pointer)
该字段长为16位。只有在URG控制位为1时有效。该字段的数值表示本报文段中紧急数据的指针。 正确来讲,从数据部分的首位到紧急指针所指示的位置 为止为紧急数据。因此也可以说紧急指针指出了紧急数据的末尾在报文段中的位置。 如何处理紧急数据属于应用的问题。一般在暂时中断通信,或中断通信的情况下使用。例如在Web浏览器中点击停止按钮, 或者使用TELNET输入Ctrl+C 时都会有URG为1的包。 此外, 紧急指针也用作表示数据流分段的标志。 - 选项(Options)
选项字段用于提高TCP的传输性能。因为根据数据偏移(首部长度)进行控制,所以其长度最大为40字节。
另外,选项字段尽量调整其为32位的整数倍。具有代表性的选项如下表,我们从中挑些重点进行讲解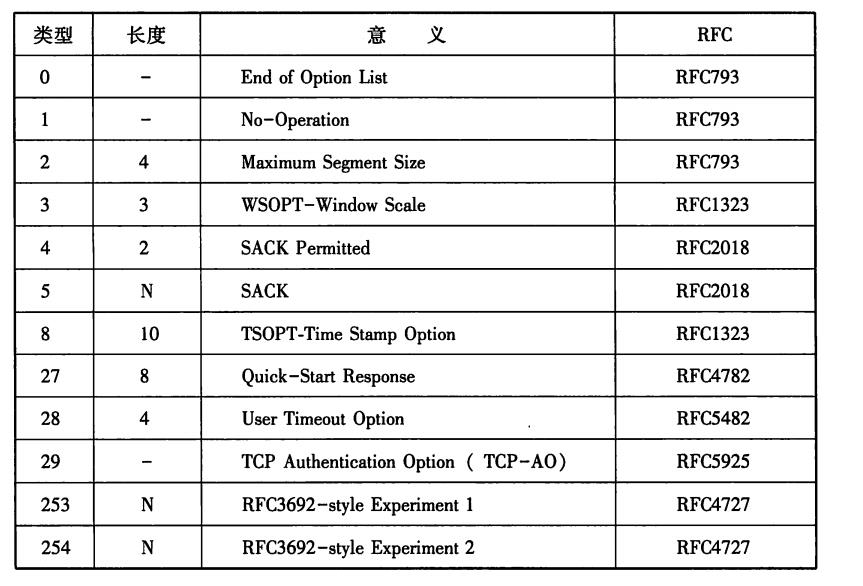
类型2的MSS选项用于在建立连接时决定最大段长度的情况。这选项用于大部分操作系统。
类型3的窗口扩大, 是一个用来改善TCP吞吐量的选项。TCP首部中窗口字段只有16位。 因此在TCP包的往返时间(RTT) ) 内,只能发送最大64K字节的 数据"。如果采用了该选项,窗口的最大值可以扩展到1G字节。由此,即使在一个RTT较长的网络环境中, 也能达到较高的吞吐量。
类型8时间戳字段选项,用于高速通信中对序列号的管理。若要将几个G的数据高速转发到网络时, 32位序列号的值可能会迅速使用完。在传输不稳定的网络环境下,就有可能会在较晚的时间点却收到散布在网络中的一个较早序列号的包。 而如果接收端对新老序列号产生混淆就无法实现可靠传输。 为了避免这个问题的发生,引人了时间戳这个选项,它可以区分新老序列号。
类型4和5用于选择确认应答(SACK:S Selective ACKnowledgement) 。TCP的确认应答一般只有1个数字, 如果数据段总以“豁牙子状态””到达的话会严重影响网络性能。有了这个选项,就可以允许最大4次的“豁牙子状态”确认应答。 因此在避免无用重发的同时,还能提高重发的速度,从而也能提高网络的吞吐量。
TCP特点
为了通过IP数据包实现可靠传输。需要考虑很多事情。
- 通过序列号与确认应答提高可靠性
- 重发超时如何确定
- 连接管理
- TCP以段为单位发送数据
- 利用窗口控制提高速度
- 窗口控制与重发控制
- 流控制
- 拥塞控制
- 提高网络利用率的规范
详细看《图解TCP/IP》和《TCP/IP详解》系列
三次握手、四次挥手
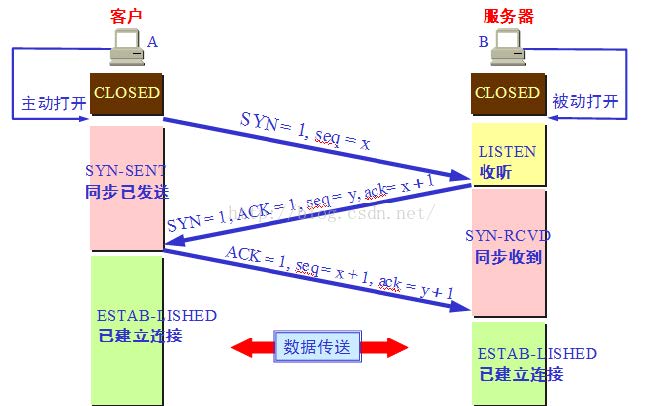
三次握手
- 第一次握手:主机 A 发送位码为 syn=1,随机产生 seq number=1234567 的数据包到服务器,主机 B 由 SYN=1 知道,A 要求建立联机;
- 第二次握手:主机 B 收到请求后要确认联机信息,向 A 发 送 ack number=( 主 机 A 的 seq+1),syn=1,ack=1,随机产生 seq=7654321 的包
- 第三次握手:主机 A 收到后检查 ack number 是否正确,即第一次发送的 seq number+1,以及位码 ack 是否为 1,若正确,主机 A 会再发送 ack number=(主机 B 的 seq+1),ack=1,主机 B 收到后确认 seq 值与 ack=1 则连接建立成功。
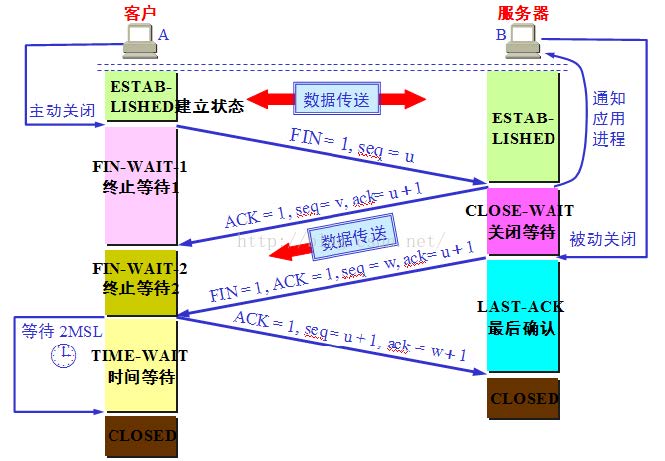
四次挥手 TCP 建立连接要进行三次握手,而断开连接要进行四次。这是由于 TCP 的半关闭造成的。因为 TCP 连 接是全双工的(即数据可在两个方向上同时传递)所以进行关闭时每个方向上都要单独进行关闭。这个单 方向的关闭就叫半关闭。当一方完成它的数据发送任务,就发送一个 FIN 来向另一方通告将要终止这个 方向的连接。
- 关闭客户端到服务器的连接:首先客户端 A 发送一个 FIN,用来关闭客户到服务器的数据传送, 然后等待服务器的确认。其中终止标志位 FIN=1,序列号 seq=u
- 服务器收到这个 FIN,它发回一个 ACK,确认号 ack 为收到的序号加 1。
- 关闭服务器到客户端的连接:也是发送一个 FIN 给客户端。
- 客户段收到 FIN 后,并发回一个 ACK 报文确认,并将确认序号 seq 设置为收到序号加 1。 首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
主机 A 发送 FIN 后,进入终止等待状态, 服务器 B 收到主机 A 连接释放报文段后,就立即 给主机 A 发送确认,然后服务器 B 就进入 close-wait 状态,此时 TCP 服务器进程就通知高 层应用进程,因而从 A 到 B 的连接就释放了。此时是“半关闭”状态。即 A 不可以发送给 B,但是 B 可以发送给 A。此时,若 B 没有数据报要发送给 A 了,其应用进程就通知 TCP 释 放连接,然后发送给 A 连接释放报文段,并等待确认。A 发送确认后,进入 time-wait,注 意,此时 TCP 连接还没有释放掉,然后经过时间等待计时器设置的 2MSL 后,A 才进入到 close 状态。
工具
- Linux命令tcpdump、netstat
- Wireshark
- Fiddler(开发测试、https抓包)
Netty
Netty 是一个高性能、异步事件驱动的NIO 框架,基于JAVA NIO 提供的API 实现。它提供了对 TCP、UDP 和文件传输的支持,作为一个异步NIO 框架,Netty 的所有IO 操作都是异步非阻塞 的,通过Future-Listener 机制,用户可以方便的主动获取或者通过通知机制获得IO 操作结果。
Netty高性能
在IO 编程过程中,当需要同时处理多个客户端接入请求时,可以利用多线程或者IO 多路复用技术 进行处理。IO 多路复用技术通过把多个IO 的阻塞复用到同一个select 的阻塞上,从而使得系统在 单线程的情况下可以同时处理多个客户端请求。与传统的多线程/多进程模型比,I/O 多路复用的 最大优势是系统开销小,系统不需要创建新的额外进程或者线程,也不需要维护这些进程和线程 的运行,降低了系统的维护工作量,节省了系统资源。 与Socket 类和ServerSocket 类相对应,NIO也提供了SocketChannel 和ServerSocketChannel 两种不同的套接字通道实现。
多路复用通信方式
Netty 架构按照Reactor 模式设计和实现,
它的服务端通信序列图如下: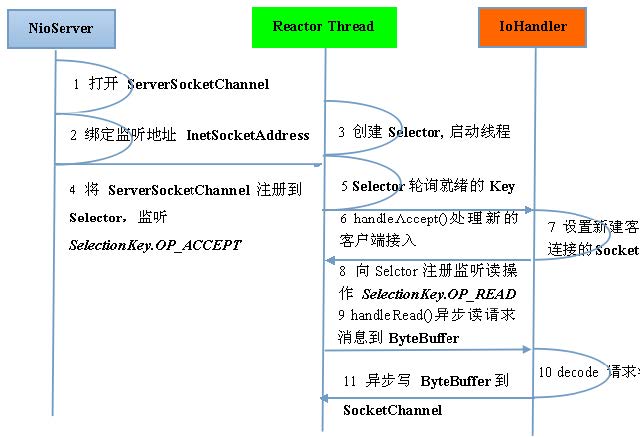
客户端通信序列图如下: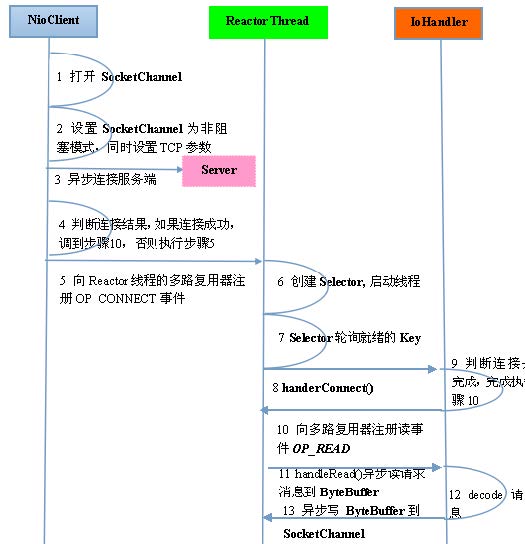
Netty 的IO 线程NioEventLoop 由于聚合了多路复用器Selector,可以同时并发处理成百上千个 客户端Channel,由于读写操作都是非阻塞的,这就可以充分提升IO 线程的运行效率,避免由于 频繁IO 阻塞导致的线程挂起。
异步通讯NIO
由于Netty 采用了异步通信模式,一个IO 线程可以并发处理N 个客户端连接和读写操作,这从根 本上解决了传统同步阻塞IO 一连接一线程模型,架构的性能、弹性伸缩能力和可靠性都得到了极 大的提升。
零拷贝(DIRECT BUFFERS使用堆外直接内存)
- Netty 的接收和发送ByteBuffer 采用DIRECT BUFFERS,使用堆外直接内存进行Socket 读写, 不需要进行字节缓冲区的二次拷贝。如果使用传统的堆内存(HEAP BUFFERS)进行Socket 读写, JVM 会将堆内存Buffer 拷贝一份到直接内存中,然后才写入Socket 中。相比于堆外直接内存, 消息在发送过程中多了一次缓冲区的内存拷贝。
- Netty 提供了组合Buffer 对象,可以聚合多个ByteBuffer 对象,用户可以像操作一个Buffer 那样 方便的对组合Buffer 进行操作,避免了传统通过内存拷贝的方式将几个小Buffer 合并成一个大的 Buffer。
- Netty 的文件传输采用了transferTo方法,它可以直接将文件缓冲区的数据发送到目标Channel, 避免了传统通过循环write 方式导致的内存拷贝问题
内存池(基于内存池的缓冲区重用机制)
随着JVM 虚拟机和JIT 即时编译技术的发展,对象的分配和回收是个非常轻量级的工作。但是对于缓 冲区Buffer,情况却稍有不同,特别是对于堆外直接内存的分配和回收,是一件耗时的操作。为了尽 量重用缓冲区,Netty 提供了基于内存池的缓冲区重用机制。
高效的Reactor线程模型
常用的Reactor 线程模型有三种,Reactor 单线程模型, Reactor 多线程模型, 主从Reactor 多线程模型。
- Reactor单线程模型
Reactor 单线程模型,指的是所有的IO 操作都在同一个NIO 线程上面完成,NIO 线程的职责如下:
- 作为NIO 服务端,接收客户端的TCP 连接;
- 作为NIO 客户端,向服务端发起TCP 连接;
- 读取通信对端的请求或者应答消息;
- 向通信对端发送消息请求或者应答消息。
由于Reactor 模式使用的是异步非阻塞IO,所有的IO 操作都不会导致阻塞,理论上一个线程可以独
立处理所有IO 相关的操作。从架构层面看,一个NIO 线程确实可以完成其承担的职责。例如,通过
Acceptor 接收客户端的TCP 连接请求消息,链路建立成功之后,通过Dispatch 将对应的ByteBuffer
派发到指定的Handler 上进行消息解码。用户Handler 可以通过NIO 线程将消息发送给客户端。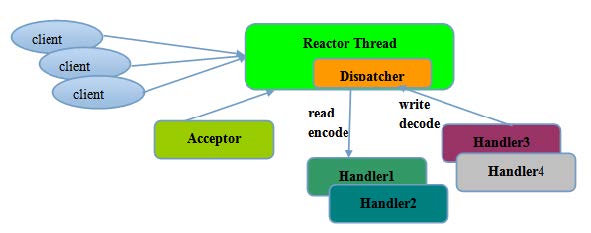
- Reactor 多线程模型
Rector 多线程模型与单线程模型最大的区别就是有一组NIO 线程处理IO 操作。 有专门一个
NIO 线程-Acceptor 线程用于监听服务端,接收客户端的TCP 连接请求; 网络IO 操作-读、写
等由一个NIO 线程池负责,线程池可以采用标准的JDK 线程池实现,它包含一个任务队列和N
个可用的线程,由这些NIO 线程负责消息的读取、解码、编码和发送;
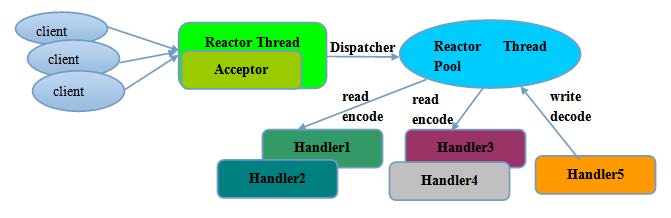
- 主从Reactor多线程模型
服务端用于接收客户端连接的不再是个1 个单独的NIO 线程,而是一个独立的NIO 线程池。
Acceptor 接收到客户端TCP 连接请求处理完成后(可能包含接入认证等),将新创建的
SocketChannel 注册到IO 线程池(sub reactor 线程池)的某个IO 线程上,由它负责
SocketChannel 的读写和编解码工作。Acceptor 线程池仅仅只用于客户端的登陆、握手和安全
认证,一旦链路建立成功,就将链路注册到后端subReactor 线程池的IO 线程上,由IO 线程负
责后续的IO 操作。
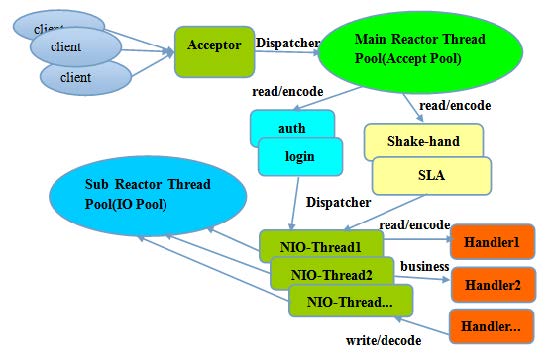
无锁设计、线程绑定
Netty 采用了串行无锁化设计,在IO 线程内部进行串行操作,避免多线程竞争导致的性能下降。
表面上看,串行化设计似乎CPU 利用率不高,并发程度不够。但是,通过调整NIO 线程池的线程
参数,可以同时启动多个串行化的线程并行运行,这种局部无锁化的串行线程设计相比一个队列-
多个工作线程模型性能更优。

Netty 的NioEventLoop 读取到消息之后,直接调用ChannelPipeline 的
fireChannelRead(Object msg),只要用户不主动切换线程,一直会由NioEventLoop 调用
到用户的Handler,期间不进行线程切换,这种串行化处理方式避免了多线程操作导致的锁
的竞争,从性能角度看是最优的。
高性能的序列化框架
Netty 默认提供了对Google Protobuf 的支持,通过扩展Netty 的编解码接口,用户可以实现其它的 高性能序列化框架,例如Thrift 的压缩二进制编解码框架。
- SO_RCVBUF 和SO_SNDBUF:通常建议值为128K 或者256K。 大包封小包,防止网络阻塞
- SO_TCPNODELAY:NAGLE 算法通过将缓冲区内的小封包自动相连,组成较大的封包,阻止大量 小封包的发送阻塞网络,从而提高网络应用效率。但是对于时延敏感的应用场景需要关闭该优化算 法。 软中断Hash值和CPU绑定
- 软中断:开启RPS 后可以实现软中断,提升网络吞吐量。RPS 根据数据包的源地址,目的地址以 及目的和源端口,计算出一个hash 值,然后根据这个hash 值来选择软中断运行的cpu,从上层 来看,也就是说将每个连接和cpu 绑定,并通过这个hash 值,来均衡软中断在多个cpu 上,提升 网络并行处理性能。
Canal
MySQL
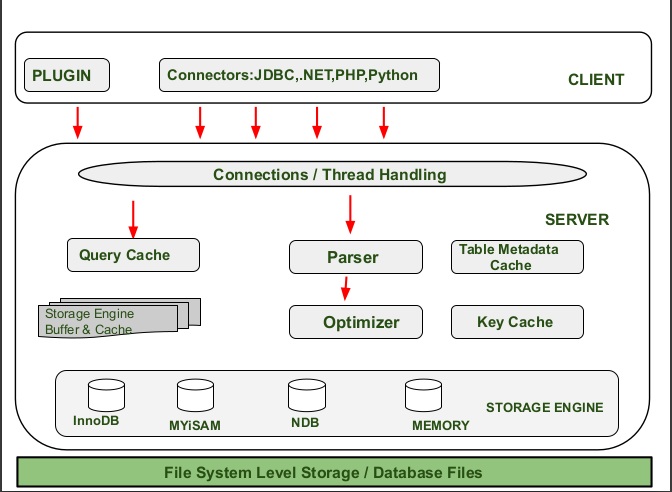
体系结构
mysql体系结构:
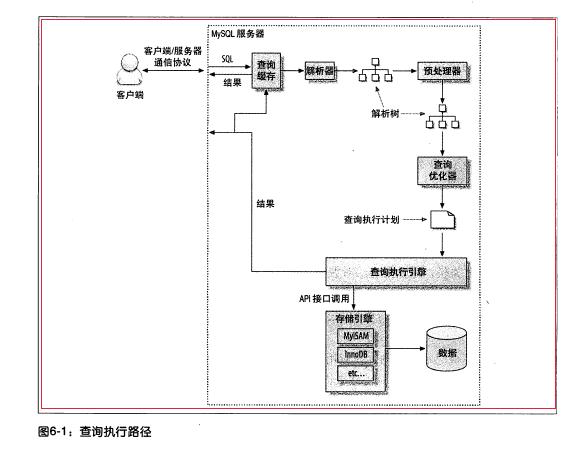
一个MySQL查询的内部执行流程:
线程模型
MySQL的内部实现手册对MySQL有哪些线程做了陈述。 10.10 Threads|MySQL Internals Manual
列举一些重要的线程
- The main thread. Runs at CONNECT_PRIOR priority. Calls thr_setconcurrency() if it is available at compile time; this call is generally assumed to exist only on Solaris, its value should reflect the number of physical CPUs.
- The "bootstrap" thread. See handle_bootstrap() in sql_parse.cc. The mysql_install_db script starts a server with an option telling it to start this thread and read commands in from a file. Used to initialize the grant tables. Runs once and then exits.
- The "maintenance" thread. See sql_manager_cc. Like the old "sync" daemon in unix, this thread occasionally flushes MyISAM tables to disk. InnoDB has a separate maintenance thread, but BDB also uses this one to occasionally call berkeley_cleanup_log_files(). Begins at startup and persists until shutdown.
- The "handle TCP/IP sockets" thread. See handle_connections_sockets() in mysqld.cc. Loop with a select() function call, to handle incoming connections.
InnoDB的线程
- The I/O handler threads, See io_handler_thread().
- Two "watchmen" threads: srv_lock_timeout_and_monitor_thread(), and srv_error_monitor_thread().
- The master thread "which does purge and other utility operations", See srv_master_thread().
表
索引组织表
在InnoDB存储引擎中, 表都是根据主键顺序组织存放的, 这种存储方式的表称 为索引组织表(index organized table) 。
在InnoDB存储引擎表中, 每张表都有个主键 (PrimaryKey) , 如果在创建表时没有显式地定义主键, 则InnoDB存储引擎会按如下方式选择或创建主键
- 首先判断表中是否有非空的唯一索引(Unique NOT NULL) , 如果有, 则该列即 为主键。
- 如果不符合上述条件, InnoDB存储引擎自动创建一个6字节大小的指针。
当表中有多个非空唯一索引时, InnoDB存储引擎将选择建表时第一个定义的非空唯一索引为主键。 这里需要非常注意的是,主键的选择根据的是定义索引的顺序,而不是 建表时列的顺序。
InnoDB逻辑存储结构
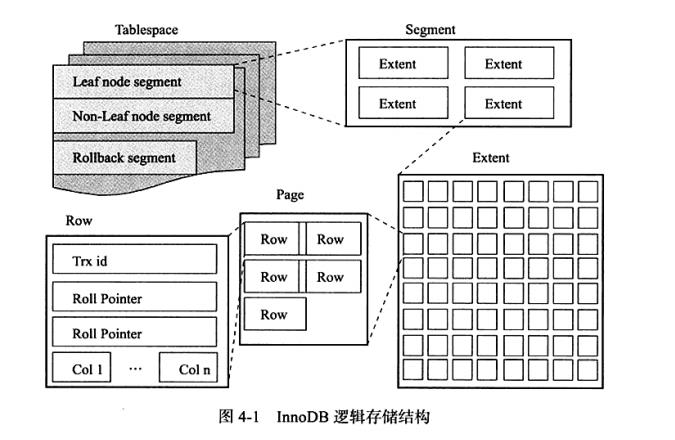
- 表空间
- 段
- 区
- 页
同大多数数据库一样, InnoDB有页(Page) 的概念(也可以称为块) , 页是InnoDB 磁盘管理的最小单位。 在InnoDB存储引擎中, 默认每个页的大小为16KB。而从 InnoDB 1.2.x版本开始, 可以通过参数innodb pagesize 将页的大小设置为4K、8K 16K。若设置完成, 则所有表中页的大小都为innodb pagesize, 不可以对其再次进行修改。 除非通过mysqldump导人和导出操作来产生新的库。 在InnoDB存储引擎中, 常见的页类型有:- 数据页(B-treeNode)
- undo页(undo Log Page)
- 系统页(System Page)
- 事务数据页(Transaction system Page)
- 插入缓冲位图页(Insert Buffer Bitmap)
- 插入缓冲空闲列表页(Insert Buffer Free List)
- 未压缩的二进制大对象页(Uncompressed BLOB Page)
- 压缩的二进制大对象页(compressed BLOB Page)
- 行
索引
Innodb支持如下几种常见索引:
- B+树索引
- 全文索引
- 哈希索引
InnoDB存储引擎支持的哈希索引是自适应的, InnoDB存储引擎会 根据表的使用情况自动为表生成哈希索引,不能人为干预是否在一张表中生成哈希索引。
B+树索引就是传统意义上的索引,这是目前关系型数据库系统中查找最为常用和最为有效的索引。 B+树索引的构造类似于二叉树, 根据键值(KeyValue) 快速找到数据。
B+树索引
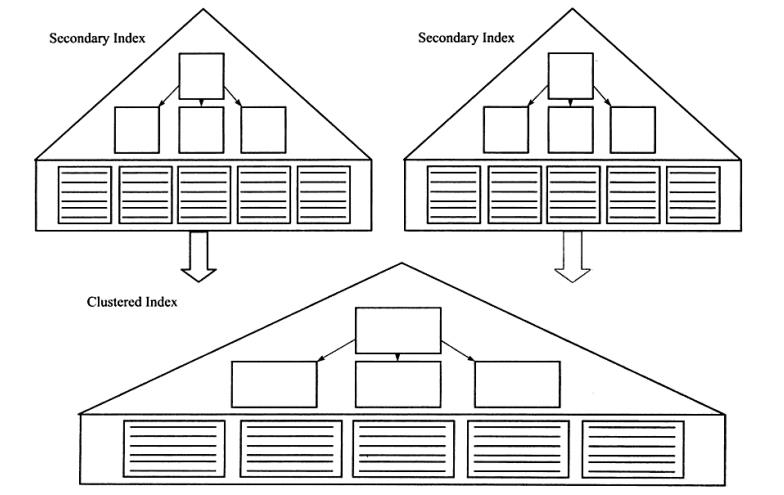
聚集索引
之前已经介绍过了, InnoDB存储引擎表是索引组织表, 即表中数据按照主键顺序存 放。而聚集索引(clustered index) 就是按照每张表的主键构造一棵B+树, 同时叶子节点中存放的即为整张表的行记录数据,也将聚集索引的叶子节点称为数据页。 聚集索引的这个特性决定了索引组织表中数据也是索引的一部分。同B+树数据结构一样,每个 数据页都通过一个双向链表来进行链接。
由于实际的数据页只能按照一棵B+树进行排序,因此每张表只能拥有一个聚集索引。 在多数情况下,查询优化器倾向于采用聚集索引。因为聚集索引能够在B+树索引的叶子节点上直接找到数据。 此外,由于定义了数据的逻辑顺序,聚集索引能够特别快 地访问针对范围值的查询。查询优化器能够快速发现某一段范围的数据页需要扫描。
辅助索引
对于辅助索引(Secondary Index, ,t 也称非聚集索引),叶子节点并不包含行记录的 全部数据。 叶子节点除了包含键值以外,每个叶子节点中的索引行中还包含了一个书签 (bookmark) 。 该书签用来告诉InnoDB存储引擎哪里可以找到与索引相对应的行数据。由于InnoDB存储引擎表是索引组织表, 因此InnoDB存储引擎的辅助索引的书签就是相应 行数据的聚集索引键。
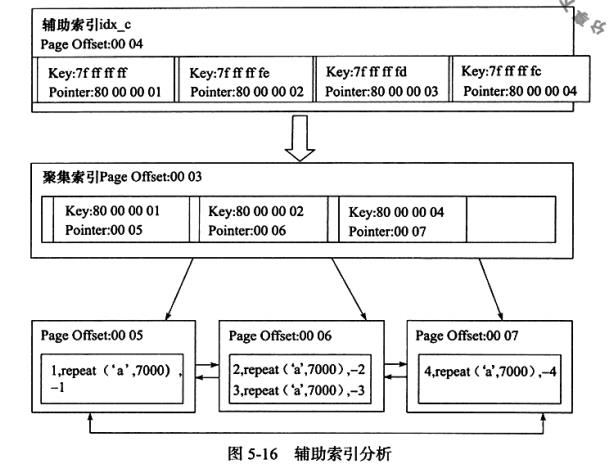
相关SQL
- 修改:alter table或create/drop index
- 查看:show index from table
联合索引
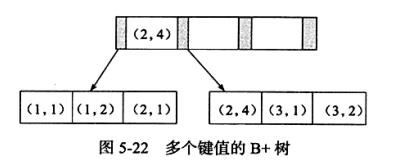
全文检索
事务
事务本身持有4个限定属性(简称ACID属性),来保证事务前后,系统始终处于“正确”的状态:
原子性(Atomicity)
一致性(Consistency)
隔离性(Isolation)
持久性(Durability)
事务隔离级别
READ UNCOMMITTED
READ COMMITTED
REPEATABLE READ
SERIALIZABLE
MySQL默认支持的隔离级别是REPEATABLE READ,由于MySQL的InnoDB的锁实现机制,所以实质上MySQL的REPEATABLE READ级别达到了SQL标准的SERIALIZABLE级别。 这不影响性能,在一些文献上可知,采用SERIALIZABLE级别其实性能甚至优于REPEATABLE READ。
分类
- 扁平事务
是事务类型中最简单的一种,但在实际生产环境中,这是使用最为频繁的事务。 所有操作处于同一层次,其由BEGIN WORK开始,由COMMIT WORK或ROLLBACK WORK结束,期间操作是原子的, 要么执行,要么都回滚。
缺点:不能提交或回滚事务中的某一部分。 - 带有保存点的扁平事务
在扁平事务的基础上支持在事务执行过程回滚到同一事务中较早的一个状态。 - 链事务
可视为保存点的扁平事务的一种变种。当发生系统崩溃时,所有保存点都消失,保存点非持久的。 - 嵌套事务
是一个层次结构框架,由一个顶层事务控制着各个层次的事务。顶层事务之下嵌套的事务被称为子事务。 - 分布式事务
通常是一个在分布式环境下运行的扁平事务,因此需要根据数据所在位置访问网络中的不同节点。
事务的实现
事务隔离性由锁来实现。原子性、一致性、持久性通过数据库的redo log和undo log来完成。
redo log称为重做日志, 用来保证事务的原子性和持久性。
undo log用来保证事务的一致性。
有的DBA或许会认为undo是redo的逆过程, 其实不然。
redo和undo的作用都可以视为是一种恢复操作, redo恢复提交事务修改的页操作, 而undo回滚行记录到某个特定版本。
因此两者记录的内容不同, redo通常是物理日志, 记录的是页的物理修改操作。
undo是逻辑日志, 根据每行记录进行记录。
redo
重做日志用来实现事务的持久性,即事务ACID的D。
redoLog 是重做日志文件是记录数据修改之后的值,用于持久化到磁盘中。
redo log包括两部分:
一是内存中的日志缓冲(redo log buffer),该部分日志是易失性的;
二是磁盘上的重做日志文件(redo log file),该部分日志是持久的。
由引擎层的InnoDB引擎实现,是物理日志,记录的是物理数据页修改的信息,比如“某个数据页上内容发生了哪些改动”。
当一条数据需要更新时,InnoDB会先将数据更新,然后记录redoLog 在内存中,然后找个时间将redoLog的操作执行到磁盘上的文件上。
不管是否提交成功我都记录,你要是回滚了,那我连回滚的修改也记录。
它确保了事务的持久性。每个InnoDB存储引擎至少有1个重做日志文件组(group),每个文件组下至少有2个重做日志文件,如默认的ib_logfile0和ib_logfile1。
为了得到更高的可靠性,用户可以设置多个的镜像日志组(mirrored log groups),将不同的文件组放在不同的磁盘上,以此提高重做日志的高可用性。
在日志组中每个重做日志文件的大小一致,并以循环写入的方式运行。InnoDB存储引擎先写重做日志文件1,当达到文件的最后时,会切换至重做日志文件2,再当重做日志文件2也被写满时,会再切换到重做日志文件1中。
undo
undoLog 也就是我们常说的回滚日志文件
主要用于事务中执行失败,进行回滚,以及MVCC中对于数据历史版本的查看。
由引擎层的InnoDB引擎实现,是逻辑日志,记录数据修改被修改前的值,比如"把id='B' 修改为id = 'B2',
那么undo日志就会用来存放id ='B'的记录”。当一条数据需要更新前,会先把修改前的记录存储在undolog中,如果这个修改出现异常,则会使用undo日志来实现回滚操作,保证事务的一致性。
当事务提交之后,undo log并不能立马被删除,而是会被放到待清理链表中,待判断没有事物用到该版本的信息时才可以清理相应undolog。
它保存了事务发生之前的数据的一个版本,用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读。
binlog和redolog的区别
- redolog是在InnoDB存储引擎层产生,而binlog是MySQL数据库的上层服务层产生的。
- 两种日志记录的内容形式不同。MySQL的binlog是逻辑日志,其记录是对应的SQL语句,对应的事务。而innodb存储引擎层面的重做日志是物理日志,是关于每个页(Page)的更改的物理情况。
- 两种日志与记录写入磁盘的时间点不同,binlog日志只在事务提交完成后进行一次写入。而innodb存储引擎的重做日志在事务进行中不断地被写入,并日志不是随事务提交的顺序进行写入的。
- binlog不是循环使用,在写满或者重启之后,会生成新的binlog文件,redolog是循环使用。
- binlog可以作为恢复数据使用,主从复制搭建,redolog作为异常宕机或者介质故障后的数据恢复使用。
purge
purge用于最终完成delete和update操作。这样设计是因为InnoDB存储引擎支持MVCC,所以记录不能在事务提交时立即进行处理。
group commit
MVCC
MySQL · 引擎特性 · InnoDB MVCC 相关实现|阿里云RDS-数据库内核组 一文理解Mysql MVCC|强哥叨逼叨|zhihu
对于事务操作的统计
由于InnoDB存储引擎是支持事务的, 因此InnoDB存储引擎的应用需要在考虑每秒 请求数(Question Per Second, QPS) 的同时, 应该关注每秒事务处理的能力(Transaction Per Second, TPS) 。
计算TPS的方法是(com_commit+com rollback) /time。 但是利用这种方法进行计算的前提是:所有的事务必须都是显式提交的,如果存在隐式地提交和回滚(默认 autocommit=1), 不会计算到com commit和com rollback变量中。
分布式事务
XA事务。
锁
lock、latch
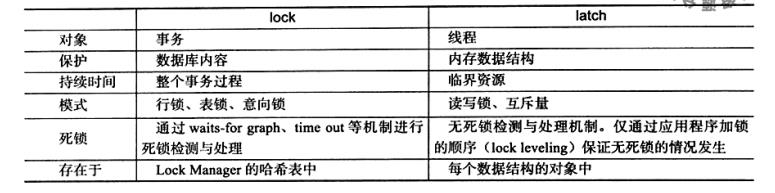
- latch为一轻量级锁,其目的是用来保证并发线程操作临界资源的正确性,并且通常没有死锁检测的机制。
- lock的对象为事务,用来锁定的是数据库中的对象,如表、页、行。
InnoDB锁
类型:
- 共享锁(S lock),允许事务读一行数据。
- 排它锁(X lock),允许事务删除或更新一行数据。
两种锁都是行锁,排它锁与所有包括他自己的锁都不兼容。而共享锁仅仅与共享锁兼容。 此外,InnoDB引擎支持多粒度锁定,这种锁允许事务在行级上的锁和表上的锁同时存在。 InnoDB引入意向锁(Intension Lock)做支持。
InnoDB存储引擎支持意向锁设计比较简练,其意向锁即为表级别的锁。
- 意向共享锁(IS lock),事务想要获得一张表中某几行的共享锁。
- 意向排他锁(IX lock),事务想要获得一张表中某几行的排他锁。
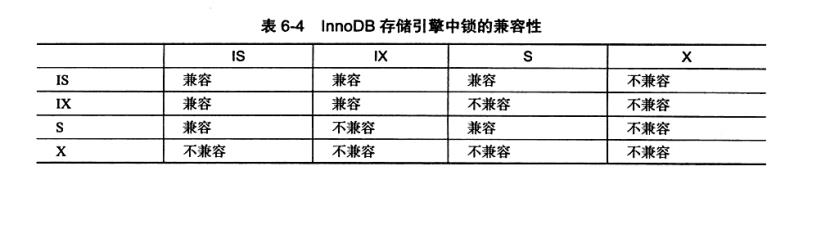
可通过show engine innodb status命令查看当前锁请求。
一致性非锁定读与MVCC
一致性的非锁定读(consistent nonlocking read)是指InnoDB存储引擎通过行多版本控制(multi versioning) 的方式来读取当前执行时间数据库中行的数据。 如果读取的行正在执行DELETE或UPDATE操作, 这时读取操作不会因此去等待行上锁的释放。 相反地, InnoDB存储引擎会去读取行的一个快照数据。
图6-4直观地展现了InnoDB 存储引擎一致性的非锁定读。之所以称其为非锁定读,因为不需要等待访问的行上X锁的释放。
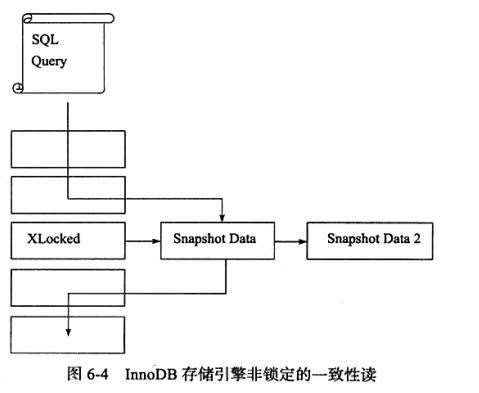
快照数据是指该行的之前版本的数据, 该实现是通过undo段来完成。而undo用来在事务中回滚数据,因此快照数据本身是没有额外的开销。此外,读取快照数据是不需要上锁的,因为没有事务需要对历史的数据进行修改操作。
可以看到, 非锁定读机制极大地提高了数据库的并发性。在InnoDB存储引擎的默认设置下,这是默认的读取方式, 即读取不会占用和等待表上的锁。 但是在不同事务隔 离级别下,读取的方式不同,并不是在每个事务隔离级别下都是采用非锁定的一致性 读。此外,即使都是使用非锁定的一致性读,但是对于快照数据的定义也各不相同。
通过上图可以知道,快照数据其实就是当前行数据之前的历史版本,每行记录可能有多个版本。一个行记录可能有不止一个快照数据, ,一般称这 种技术为行多版本技术。由此带来的并发控制, 称之为多版本并发控制(Multi Version Concurrency Control, MVCC) 。
MVCC多版本并发控制是MySQL中基于乐观锁理论实现隔离级别的方式,用于读已提交和可重复读取隔离级别的实现。 在MySQL中,会在表中每一条数据后面添加两个字段:最近修改该行数据的事务ID,指向该行(undolog表中)回滚段的指针。 Read View判断行的可见性,创建一个新事务时,copy一份当前系统中的活跃事务列表。意思是,当前不应该被本事务看到的其他事务id列表。已提交读隔离级别下的事务在每次查询的开始都会生成一个独立的ReadView,而可重复读隔离级别则在第一次读的时候生成一个ReadView,之后的读都复用之前的ReadView。
锁算法
InnoDB存储引擎有三种行锁的算法:
- Record lock
- Gap lock,间隙锁,锁定范围,但不包括记录本身
- Next-key lock, gap lock+record lock,既锁范围也锁记录。
# Next-Key Lock
InnoDB 采用 Next-Key Lock 解决幻读问题(Phantom Problem)。 Phantom Problem是指同一事务下,连续执行两次同样的SQL语句可能导致不同的结果,第二次的SQL语句可能会返回之前不存在的行。
在insert into test(xid) values (1), (3), (5), (8), (11);后,由于xid上是有索引的,该算法总是会去锁住索引记录。 现在,该索引可能被锁住的范围如下:(-∞, 1], (1, 3], (3, 5], (5, 8], (8, 11], (11, +∞)。 Session A(select * from test where id = 8 for update)执行后会锁住的范围:(5, 8], (8, 11]。 除了锁住8所在的范围,还会锁住下一个范围,所谓Next-Key。
死锁
死锁是指两个或两个以上的事务在执行过程中,因争夺锁资源而造成的一种互相等待的现象。
解决死锁的一个最简单方式是超时回滚。 InnoDB中,参数innodb_lock_wait_timeout用来设置超时的时间。 问题是可能存在占用较多undolog回滚耗时长的问题。
另一种是方式是wait-for graph(等待图)的方式进行死锁检测。 wait-for graph要求数据库保存以下两种信息:
- 锁的信息链表
- 事务等待链表
通过上述链表可以构造出一张图,而在这个图中若存在回路,就代表存在死锁。
# 死锁概率
MySQL技术内幕[1]的6.7.2一节从数学的角度分析了死锁发生的概率,理论上发生死锁机率很低。 也从公式角度说明了影响死锁发生概率的变量(事务数量、事务操作数、操作数据集(越小越大))
乐观锁悲观锁
SQL执行顺序
SQL的执行顺序:from---where--group by---having---select---order by
分库分表
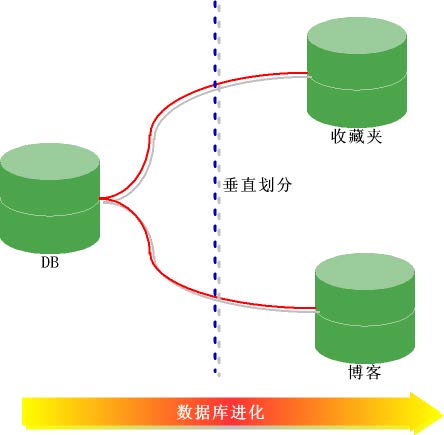
分库分表有垂直切分和水平切分两种。
- 垂直切分(按照功能模块)
将表按照功能模块、关系密切程度划分出来,部署到不同的库上。例如,我们会建立定义数
据库 workDB、商品数据库 payDB、用户数据库 userDB、日志数据库 logDB 等,分别用于
存储项目数据定义表、商品定义表、用户数据表、日志数据表等。
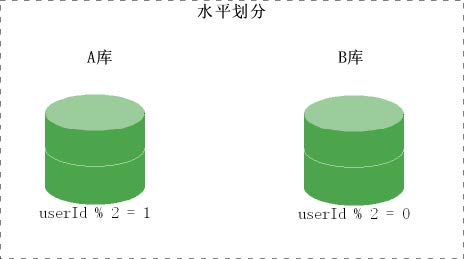
- 水平切分(按照规则划分存储)
当一个表中的数据量过大时,我们可以把该表的数据按照某种规则,例如 userID 散列,进行
划分,然后存储到多个结构相同的表,和不同的库上。
MySQL集群
HBase
HBase是目前非常热门的一款分布式KV(KeyValue,键值)数据库系统,无论是互联网行业还是其他传统IT行业都在大量使用。
历史源头:Google当年风靡一时的“三篇论文”——GFS、MapReduce、BigTable。
- 2003年Google在SOSP会议上发表了大数据历史上第一篇公认的革命性论文——《 GFS: The Google File System 》
- 2004年,Google又发表了另一篇非常重要的论文——《 MapReduce: Simplefied Data Processing on Large Clusters 》
- 2006年,Google发布了第三篇重要论文——《 BigTable: A Distributed StorageSystem for Structured Data 》
整体架构
HBase体系结构借鉴了BigTable论文,是典型的Master-Slave模型。
系统中有一个管理集群的Master节点以及大量实际服务用户读写的RegionServer节点。
除此之外,HBase中所有数据最终都存储在HDFS系统中,这与BigTable实际数据存储在GFS中相对应;系统中还有一个ZooKeeper节点,协助Master对集群进行管理。HBase体系结构如图1-6所示。
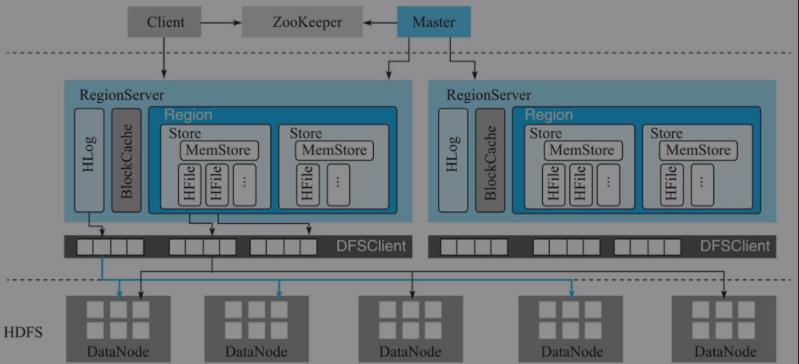
- HBase客户端
- Zookeeper
- 实现Master高可用
- 管理系统核心元数据
- 参与RegionServer宕机恢复
- 实现分布式表锁
- Master
Master主要负责HBase系统的各种管理工作:- 处理用户的各种管理请求,包括建表、修改表、权限操作、切分表、合并数据分片以及Compaction等。
- 管理集群中所有RegionServer,包括RegionServer中Region的负载均衡、RegionServer的宕机恢复以及Region的迁移等。
- 清理过期日志以及文件,Master会每隔一段时间检查HDFS中HLog是否过期、HFile是否已经被删除,并在过期之后将其删除。
- RegionServer
RegionServer主要用来响应用户的IO请求,是HBase中最核心的模块,由WAL(HLog)、BlockCache以及多个Region构成。- WAL(HLog):HLog在HBase中有两个核心作用——其一,用于实现数据的高可靠性,HBase数据随机写入时,并非直接写入HFile数据文件,而是先写入缓存,再异步刷新落盘。为了防止缓存数据丢失,数据写入缓存之前需要首先顺序写入HLog,这样,即使缓存数据丢失,仍然可以通过HLog日志恢复;其二,用于实现HBase集群间主从复制,通过回放主集群推送过来的HLog日志实现主从复制。
- BlockCache:HBase系统中的读缓存。客户端从磁盘读取数据之后通常会将数据缓存到系统内存中,后续访问同一行数据可以直接从内存中获取而不需要访问磁盘。
- Region:数据表的一个分片,当数据表大小超过一定阈值就会“水平切分”,分裂为两个Region。Region是集群负载均衡的基本单位。通常一张表的Region会分布在整个集群的多台RegionServer上,一个RegionServer上会管理多个Region,当然,这些Region一般来自不同的数据表。
一个Region由一个或者多个Store构成,Store的个数取决于表中列簇(columnfamily)的个数,多少个列簇就有多少个Store。HBase中,每个列簇的数据都集中存放在一起形成一个存储单元Store,因此建议将具有相同IO特性的数据设置在同一个列簇中。
每个Store由一个MemStore和一个或多个HFile组成。MemStore称为写缓存,用户写入数据时首先会写到MemStore,当MemStore写满之后(缓存数据超过阈值,默认128M)系统会异步地将数据f lush成一个HFile文件。 显然,随着数据不断写入,HFile文件会越来越多,当HFile文件数超过一定阈值之后系统将会执行Compact操作,将这些小文件通过一定策略合并成一个或多个大文件。
- HDFS
HBase Rowkey的散列与预分区: HBase Rowkey的散列与预分区设计|小吴蜀黍 HBase实战 | HBase Rowkey 设计指南|明惠——阿里云HBase业务架构师
数据结构
实际上,从逻辑视图来看,HBase中的数据是以表形式进行组织的, 而且和关系型数据库中的表一样,HBase中的表也由行和列构成,因此HBase非常容易理解。 但从物理视图来看,HBase是一个Map,由键值(KeyValue,KV)构成, 不过与普通的Map不同,HBase是一个稀疏的、分布式的、多维排序的Map。
逻辑视图
- table
- row 一行数据包含一个唯一标识rowkey、多个column以及对应的值。 在HBase中,一张表中所有row都按照rowkey的字典序由小到大排序。
- column 列,与关系型数据库中的列不同,HBase中的column由columnfamily(列簇)以及qualif ier(列名)两部分组成,两者中间使用":"相连。比如contents:html,其中contents为列簇,html为列簇下具体的一列。column family在表创建的时候需要指定,用户不能随意增减。一个columnfamily下可以设置任意多个qualif ier,因此可以理解为HBase中的列可以动态增加,理论上甚至可以扩展到上百万列。
- timestamp
- cell 单元格,由五元组(row, column, timestamp, type, value)组成的结构,其中type表示Put/Delete这样的操作类型,timestamp代表这个cell的版本。这个结构在数据库中实际是以KV结构存储的,其中(row, column,timestamp, type)是K,value字段对应KV结构的V。
多维稀疏排序Map
要真正理解HBase的工作原理,需要从KV数据库这个视角重新对其审视。 BigTable论文中称BigTable为"sparse,distributed, persistent multidimensional sorted map",可见BigTable本质上是一个Map结构数据库,HBase亦然,也是由一系列KV构成的。 然而HBase这个Map系统却并不简单,有很多限定词——稀疏的、分布式的、持久性的、多维的以及排序的。 接下来,我们先对这个Map进行解析,这对于之后理解HBase的工作原理非常重要。
HBase中Map的key是一个复合键,由rowkey、column family、qualif ier、type以及timestamp组成,value即为cell的值。
- 多维 key是一个复合数据结构,由多维元素构成
- 稀疏
- 排序
- 分布式
可以简单的将HTable的存储结构理解为

即HTable按Row key自动排序,每个Row包含任意数量个Columns,Columns之间按Column key自动排序,每个Column包含任意数量个Values。理解该存储结构将有助于查询结果的迭代。
物理视图
与大多数数据库系统不同,HBase中的数据是按照列簇存储的,即将数据按照列簇分别存储在不同的目录中。
行式存储、列式存储、列簇式存储
行式存储:行式存储系统会将一行数据存储在一起,一行数据写完之后再接着写下一行,最典型的如MySQL这类关系型数据库。
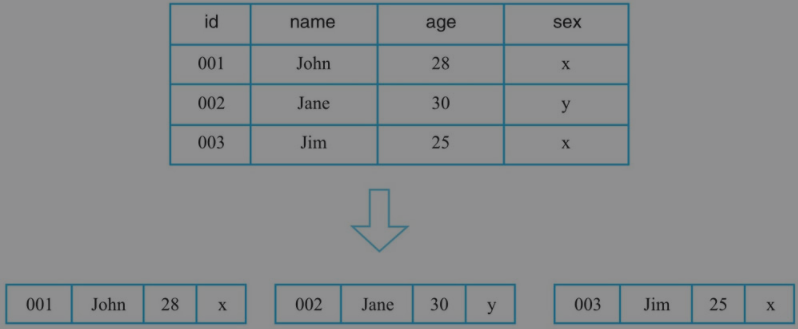 因此,这类系统仅适合于处理OLTP类型的负载,对于OLAP这类分析型负载并不擅长。
因此,这类系统仅适合于处理OLTP类型的负载,对于OLAP这类分析型负载并不擅长。列式存储:
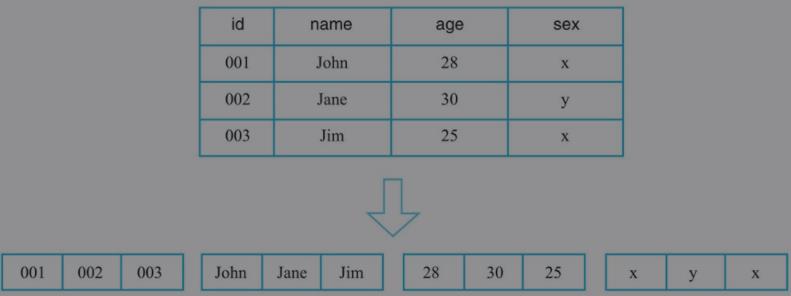 列式存储对于只查找某些列数据的请求非常高效,只需要连续读出所有待查目标列,然后遍历处理即可;但是反过来,列式存储对于获取一行的请求就不那么高效了,需要多次IO读多个列数据,最终合并得到一行数据。另外,因为同一列的数据通常都具有相同的数据类型,因此列式存储具有天然的高压缩特性。
列式存储对于只查找某些列数据的请求非常高效,只需要连续读出所有待查目标列,然后遍历处理即可;但是反过来,列式存储对于获取一行的请求就不那么高效了,需要多次IO读多个列数据,最终合并得到一行数据。另外,因为同一列的数据通常都具有相同的数据类型,因此列式存储具有天然的高压缩特性。列簇式存储 从概念上来说,列簇式存储介于行式存储和列式存储之间,可以通过不同的设计思路在行式存储和列式存储两者之间相互切换。
比如,一张表只设置一个列簇,这个列簇包含所有用户的列。HBase中一个列簇的数据是存储在一起的,因此这种设计模式就等同于行式存储。
再比如,一张表设置大量列簇,每个列簇下仅有一列,很显然这种设计模式就等同于列式存储。上面两例当然是两种极端的情况,在当前体系中不建议设置太多列簇,但是这种架构为HBase将来演变成HTAP(Hybrid Transactional and Analytical Processing)系统提供了最核心的基础。
基础数据结构和算法
HBase的一个列簇(Column Family)本质上就是一棵LSM树(Log-StructuredMerge-Tree)。 LSM树分为内存部分和磁盘部分。内存部分是一个维护有序数据集合的数据结构。 一般来讲,内存数据结构可以选择平衡二叉树、红黑树、跳跃表(SkipList)等维护有序集的数据结构,这里由于考虑并发性能,HBase选择了表现更优秀的跳跃表。 磁盘部分是由一个个独立的文件组成,每一个文件又是由一个个数据块组成。 对于数据存储在磁盘上的数据库系统来说,磁盘寻道以及数据读取都是非常耗时的操作(简称IO耗时)。 因此,为了避免不必要的IO耗时,可以在磁盘中存储一些额外的二进制数据,这些数据用来判断对于给定的key是否有可能存储在这个数据块中,这个数据结构称为布隆过滤器(Bloom Filter)。
跳表
LSM树
# LSM树的索引结构
一个LSM树的索引主要由两部分构成:内存部分和磁盘部分。内存部分是一个ConcurrentSkipListMap,Key就是前面所说的Key部分, Value是一个字节数组。数据写入时,直接写入MemStore中。随着不断写入,一旦内存占用超过一定的阈值时,就把内存部分的数据导出,形成一个有序的数据文件, 存储在磁盘上。LSM树索引结构如图2-8所示。内存部分导出形成一个有序数据文件的过程称为flush。为了避免f lush影响写入性能,会先把当前写入的MemStore设为Snapshot,不再容许新的写入操作写入这个Snapshot的MemStore。另开一个内存空间作为MemStore,让后面的数据写入。一旦Snapshot的MemStore写入完毕,对应内存空间就可以释放。这样,就可以通过两个MemStore来实现稳定的写入性能。
# 总结
LSM树本质上和B+树一样,是一种磁盘数据的索引结构。但和B+树不同的是,LSM树的索引对写入请求更友好。
因为无论是何种写入请求,LSM树都会将写入操作处理为一次顺序写,
而HDFS擅长的正是顺序写(且HDFS不支持随机写),因此基于HDFS实现的HBase采用LSM树作为索引是一种很合适的选择。
LSM树的索引一般由两部分组成,一部分是内存部分,一部分是磁盘部分。内存部分一般采用跳跃表来维护一个有序的KeyValue集合。磁盘部分一般由多个内部KeyValue有序的文件组成。
LSM树的索引结构本质是将写入操作全部转化成磁盘的顺序写入,极大地提高了写入操作的性能。
但是,这种设计对读取操作是非常不利的,因为需要在读取的过程中,通过归并所有文件来读取所对应的KV,这是非常消耗IO资源的。
因此,在HBase中设计了异步的compaction来降低文件个数,达到提高读取性能的目的。
由于HDFS只支持文件的顺序写,不支持文件的随机写,而且HDFS擅长的场景是大文件存储而非小文件,所以上层HBase选择LSM树这种索引结构是最合适的。
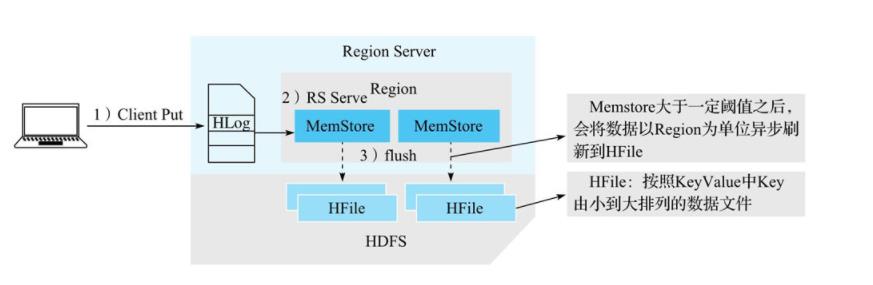
写入过程
从整体架构的视角来看,写入流程可以概括为三个阶段。
- 客户端处理阶段:客户端将用户的写入请求进行预处理,并根据集群元数据定位写入数据所在的RegionServer,将请求发送给对应的RegionServer。
- Region写入阶段:RegionServer接收到写入请求之后将数据解析出来,首先写入WAL,再写入对应Region列簇的MemStore。
- MemStore Flush阶段:当Region中MemStore容量超过一定阈值,系统会异步执行f lush操作,将内存中的数据写入文件,形成HFile。
系统特性
- HBase的优点
与其他数据库相比,HBase在系统设计以及实际实践中有很多独特的优点。
- 容量大
- 良好的可扩展性
- 稀疏性
- 高性能
HBase目前主要擅长于OLTP场景,数据写操作性能强劲,对于随机单点读以及小范围的扫描读,其性能也能够得到保证。
对于大范围的扫描读可以使用MapReduce提供的API,以便实现更高效的并行扫描。
HBase具有非常高的读写性能,基于LSM-Tree的数据结构使得HBase写入数据性能强劲, 另外得益于HBase读路径上的各种设计及优化,HBase读数据的性能也可以保持在毫秒级。 - 多版本 HBase支持多版本特性,即一个KV可以同时保留多个版本,用户可以根据需要选择最新版本或者某个历史版本。
- 支持过期
Hadoop原生支持
HBase的缺点
HBase本身不支持很复杂的聚合运算(如Join、GroupBy等)。如果业务中需要使用聚合运算,可以在HBase之上架设Phoenix组件或者Spark组件,前者主要应用于小规模聚合的OLTP场景,后者应用于大规模聚合的OLAP场景。
- HBase本身并没有实现二级索引功能,所以不支持二级索引查找。
- HBase原生不支持全局跨行事务,只支持单行事务模型。同样,可以使用Phoenix提供的全局事务模型组件来弥补HBase的这个缺陷。
应用场景
对象存储:我们知道不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中
时序数据:HBase之上有OpenTSDB模块,可以满足时序类场景的需求
推荐画像:特别是用户的画像,是一个比较大的稀疏矩阵,蚂蚁的风控就是构建在HBase之上
时空数据:主要是轨迹、气象网格之类,滴滴打车的轨迹数据主要存在HBase之中,另外在技术所有大一点的数据量的车联网企业,数据都是存在HBase之中
CubeDB OLAP:Kylin一个cube分析工具,底层的数据就是存储在HBase之中,不少客户自己基于离线计算构建cube存储在hbase之中,满足在线报表查询的需求
消息/订单:在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上
Feeds流:典型的应用就是xx朋友圈类似的应用
NewSQL:之上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求
Linux IO模型
一天速读《Unix网络编程》(上):TCP/UDP/IP + select/poll/epoll|荆赤潮
深入理解Java AIO(一)—— Java AIO的简单使用
操作系统问题集
进程通信方式
进程间通讯的7种方式排查CPU100%问题,内核态和用户态 linux top 命令 谁偷走了你的服务器性能——Strace & Ltrace篇|张文杰
Spring
reference
[1]姜承尧.MySQL技术内幕:InnoDB存储引擎.2013.北京,机械工业出版社.
[2]Baron Scbwartz等著,王小东等译.高性能MySQL(High Performance MySQL).2010.电子工业出版社.
[3]大白话讲解脏写、脏读、不可重复读和幻读|轻风|知乎
[4]我终于看懂了HBase,太不容易了...|知乎
[5]HBase原理|HBase核心原理与应用场景|大数据技术架构|知乎
[6]胡争,范欣欣.HBase原理与实践.2019.中国,机械工业出版社.
[7]MySQL索引背后的数据结构及算法原理|CodingLabs
[8]性能调优-Mysql索引数据结构详解与索引优化|鸟不拉诗
[9]10.10 Threads|MySQL Internals Manual